Au travail nous avons pour politique de builder et de maintenir nos propres images docker. Mais pour un projet perso j’utilise des images docker publiques. Je m’efforce d’utiliser au maximum des images officielles mais certaines contributions de la communauté sont parfaites pour mes besoins. Le problème est de savoir avec certitude ce que contient un image. Une image téléchargée sur un hub est une boîte noire qu’il faut inspecter avant de l’utiliser.
Cas d’images corrompues

Il y a l’exemple de l’utilisateur docker123321 qui a diffusé 17 images contenant des backdoors sur dockerhub. Parmi les images il y a tomcat, mysql ou encore cron. Avec quasiment 5 millions de téléchargements docker123321 a réussi à miner plus de 500 Moneros en plus des portes d’entrées qu’il a créées sur le serveur.
Contenu d’une image docker
Une image docker est une succession de couches (layers) qui contiennent une liste de modifications du système de fichiers. On peut faire une analogie avec GIT où chaque layer serait un commit. Au moment de la création d’un container un layer est ajouté au-dessus de ceux de l’image. Mis à part ce layer « applicatif » les layers sont en read only.
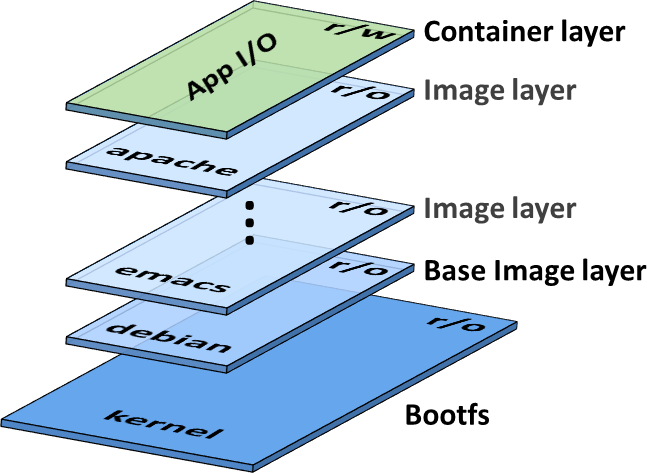
Inspecter les layers avec Dive
Dive est un programme écrit en Go qui va vous permettre d’en savoir plus sur une image avant de l’utiliser. Il ne va pas permettre de s’assurer à 100% que l’image n’est pas corrompue mais il va pouvoir nous donner des information précieuses.
Pour l’installation je vous laisse vous référer au readme du projet.
Voici un exemple d’utilisation sur l’image jonbaldie/varnish que j’utilise pour un projet perso.
➜ dive jonbaldie/varnish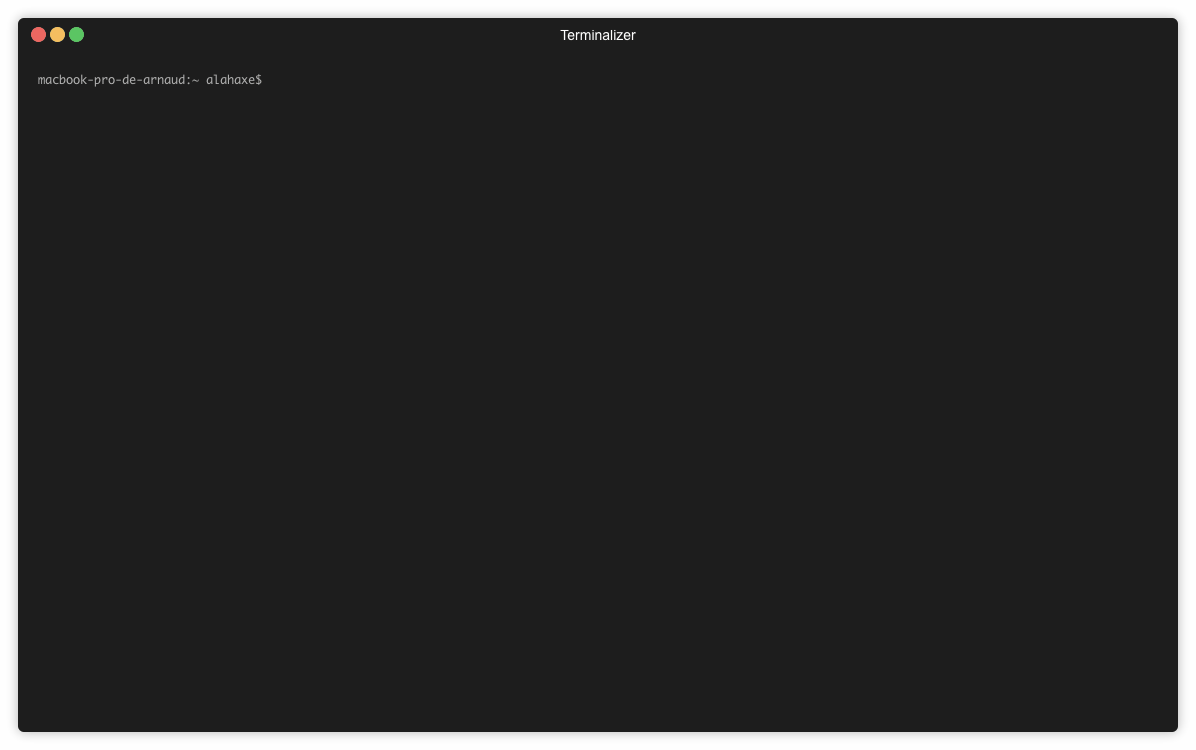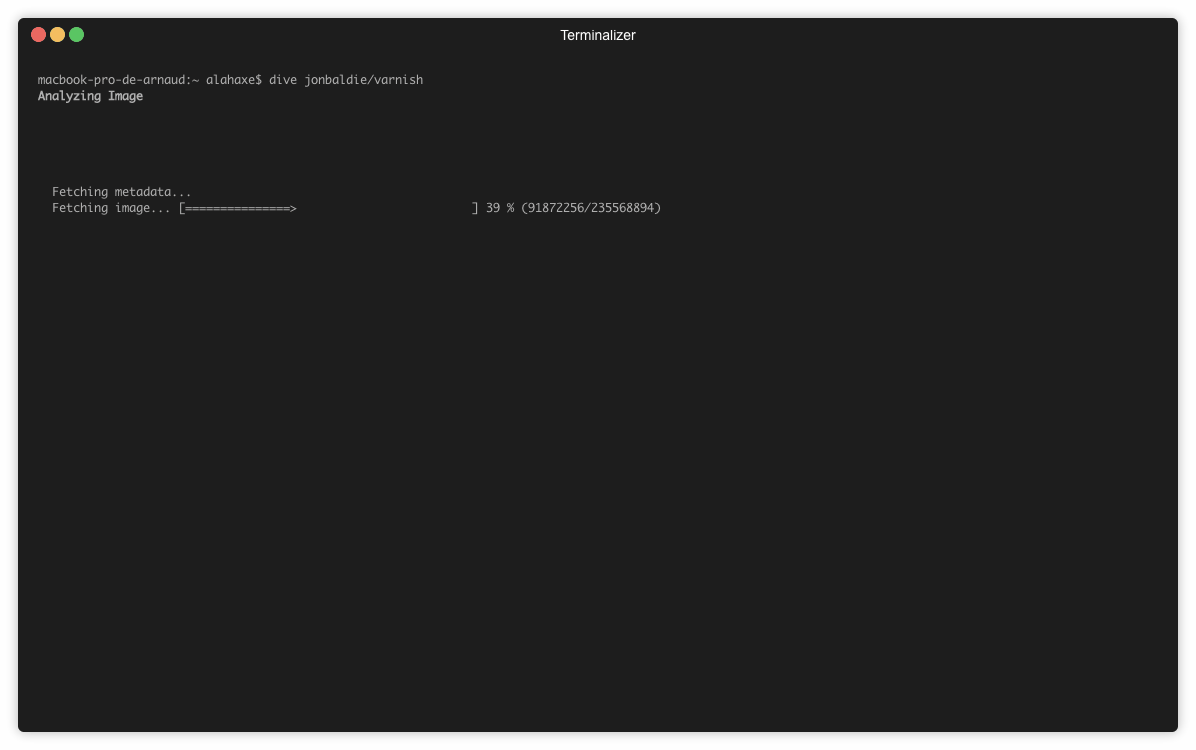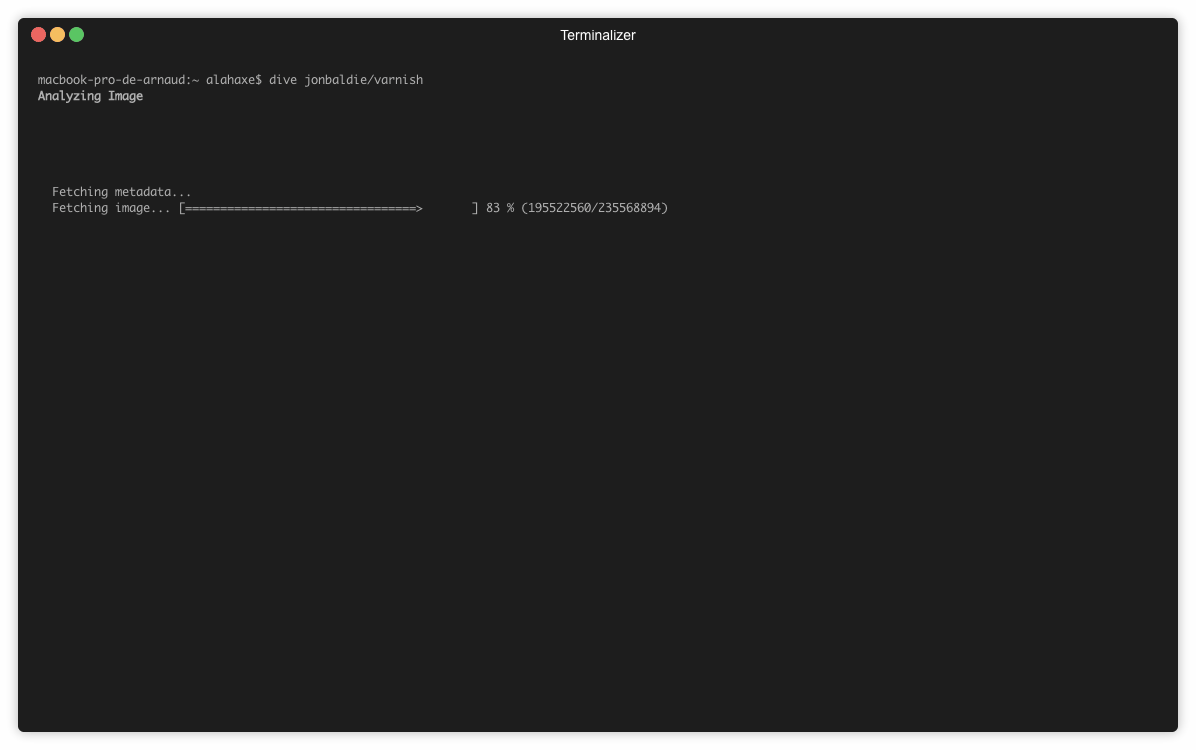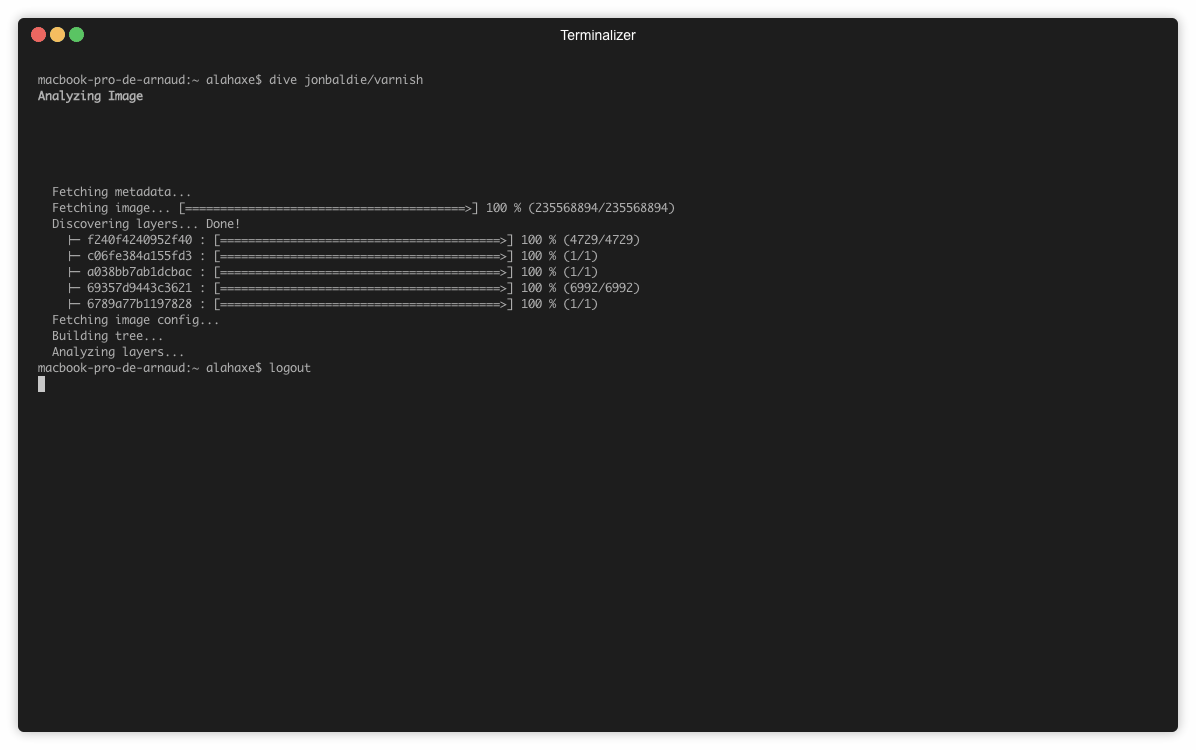
Sur l’image on a 5 layers :
- L’image de base
- L’ajout d’un script d’installation (/install.sh)
- Le résultat de l’execution du script d’install
- L’ajout du script de boot (/start.sh)
- Le chmod du script de boot
Vérifier les scripts présents dans l’image
Sur la base des informations données par Dive, il ne nous reste plus qu’à vérifier, si possible, le contenu des fichiers install.sh et start.sh
Pour un fichier toujours présent dans le dernier layer
Le fichier start.sh n’est pas supprimé après l’installation. Il est donc simple de le consulter:
➜ docker run --rm -ti jonbaldie/varnish cat /start.sh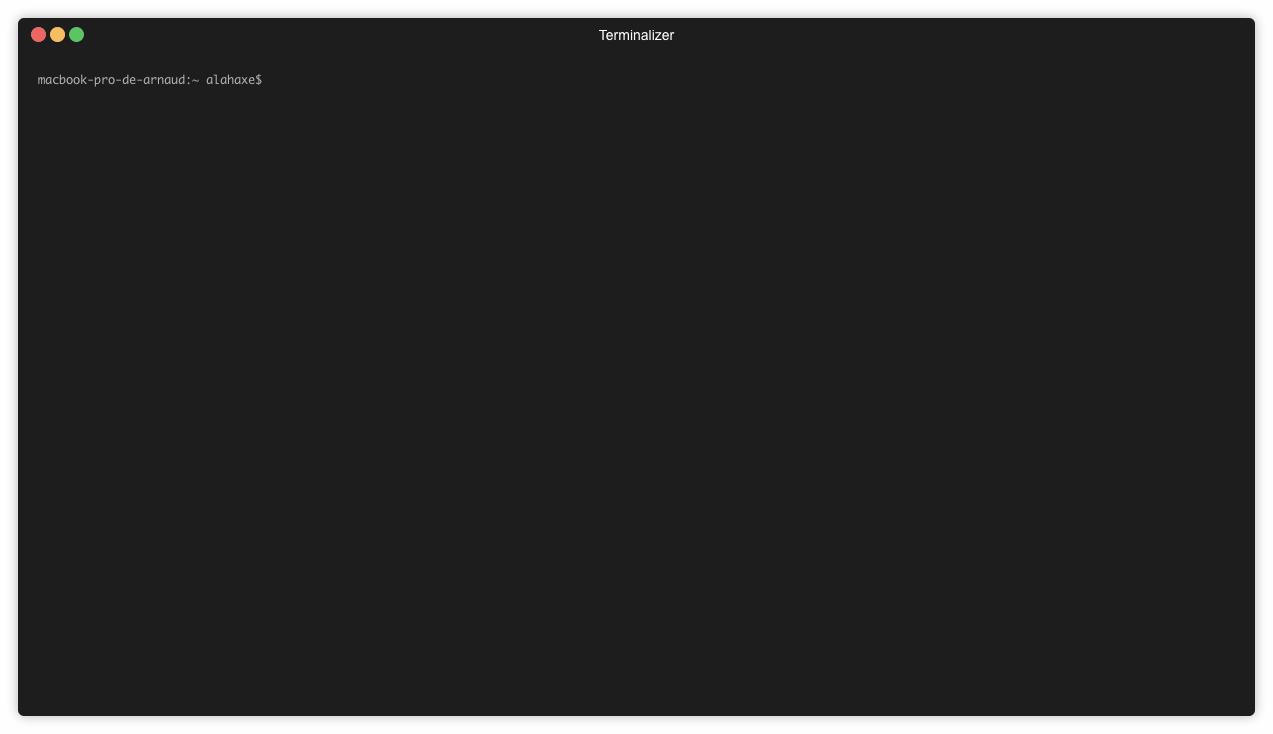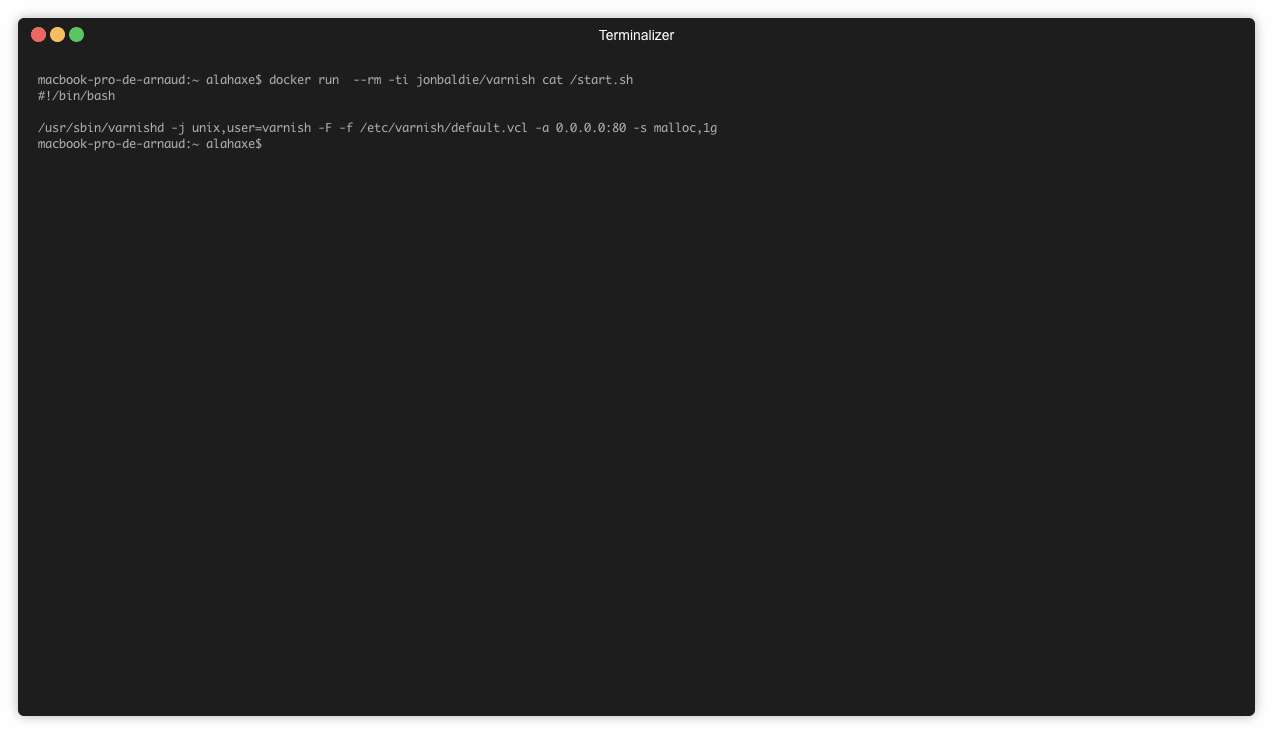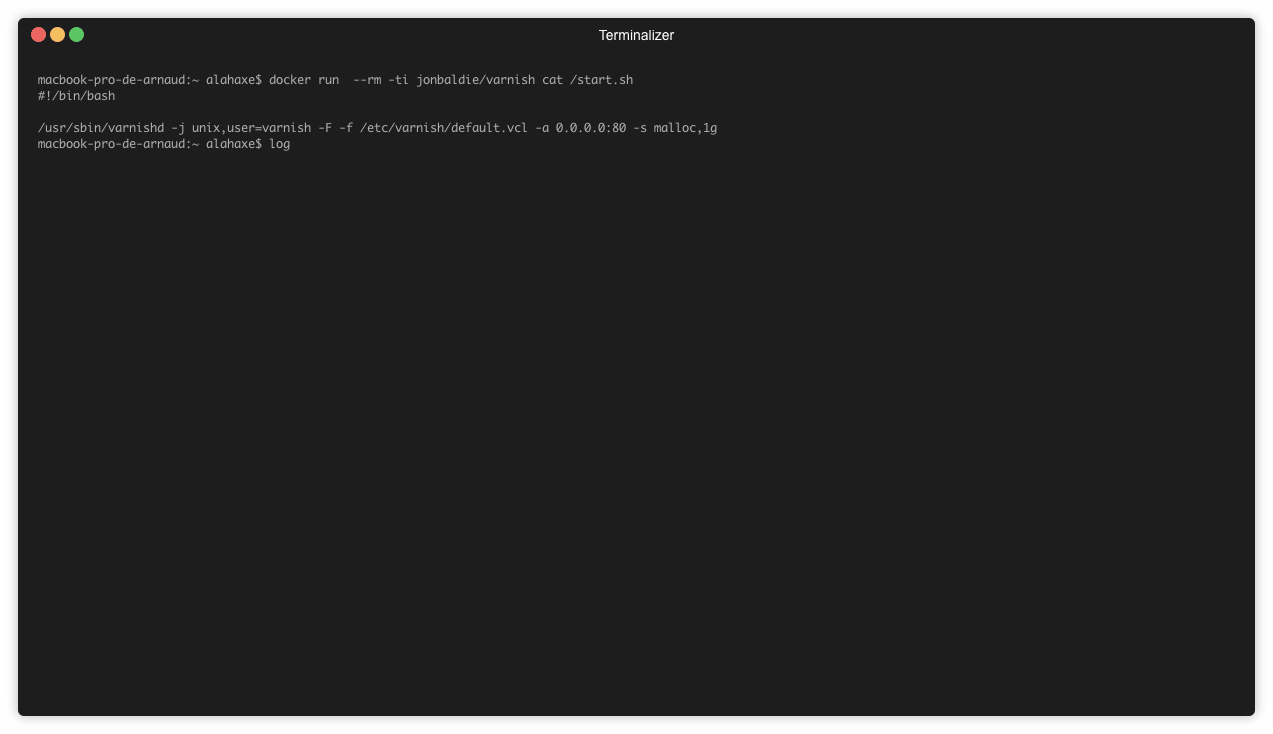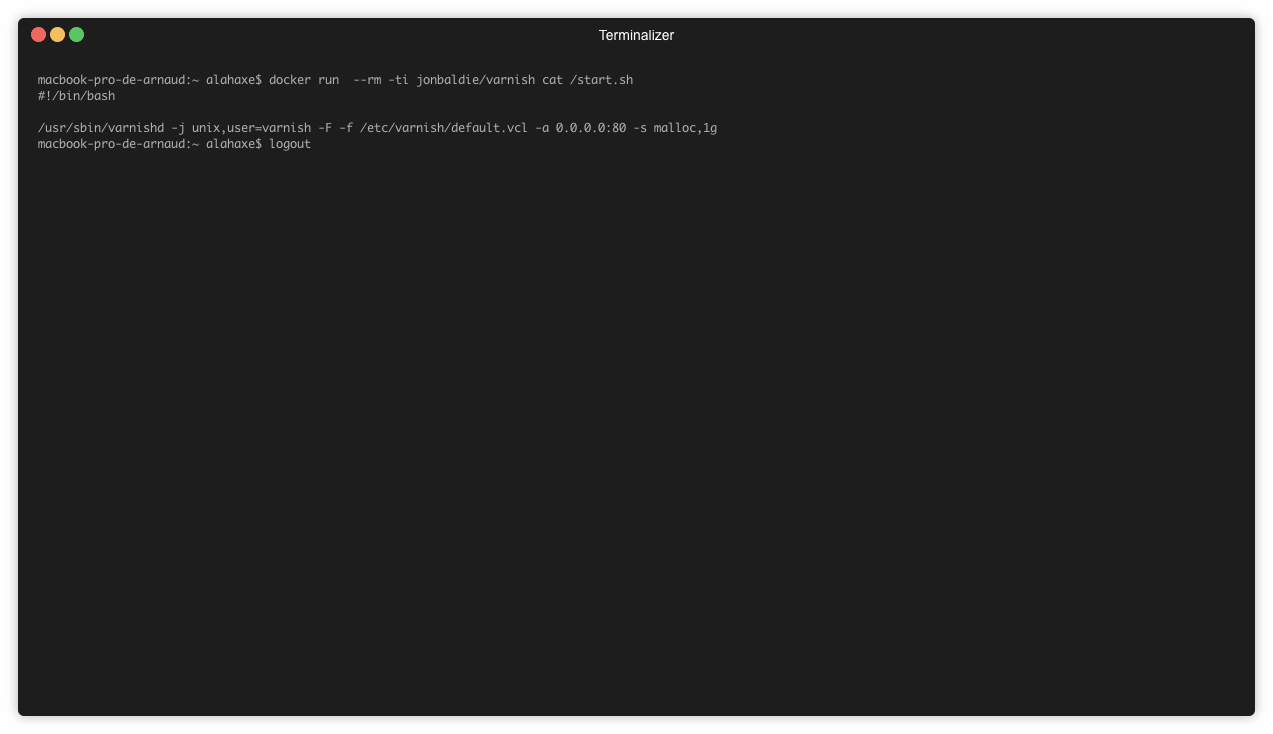
Pour un fichier non présent dans le dernier layer
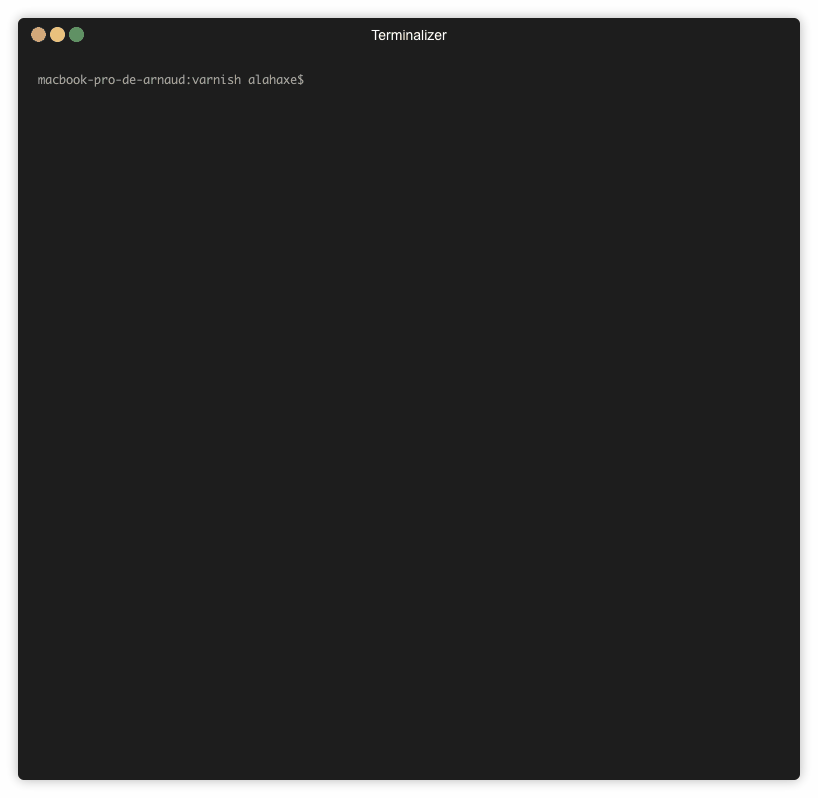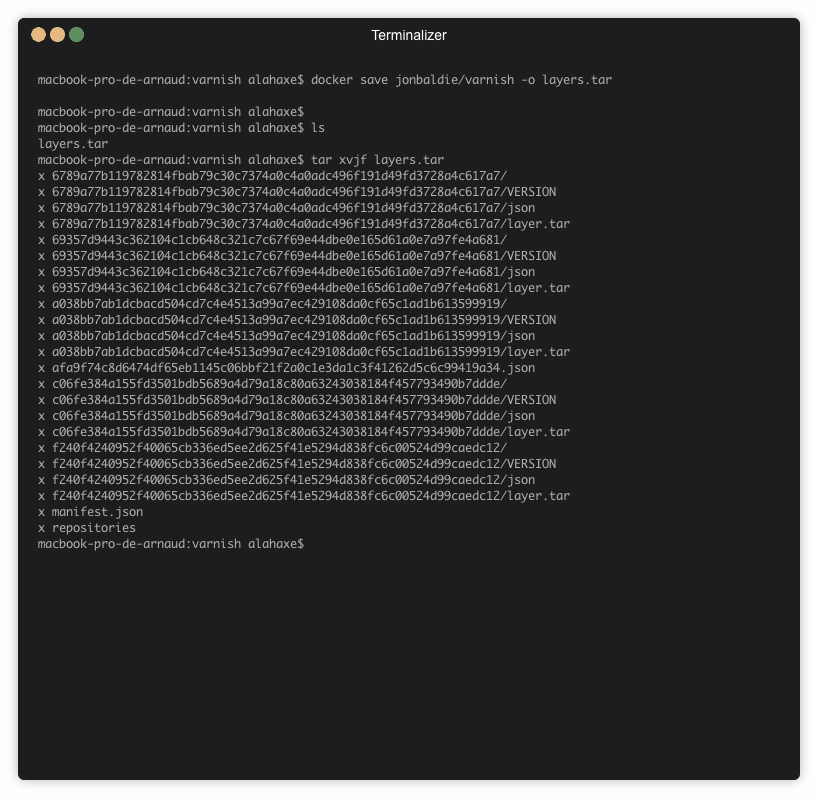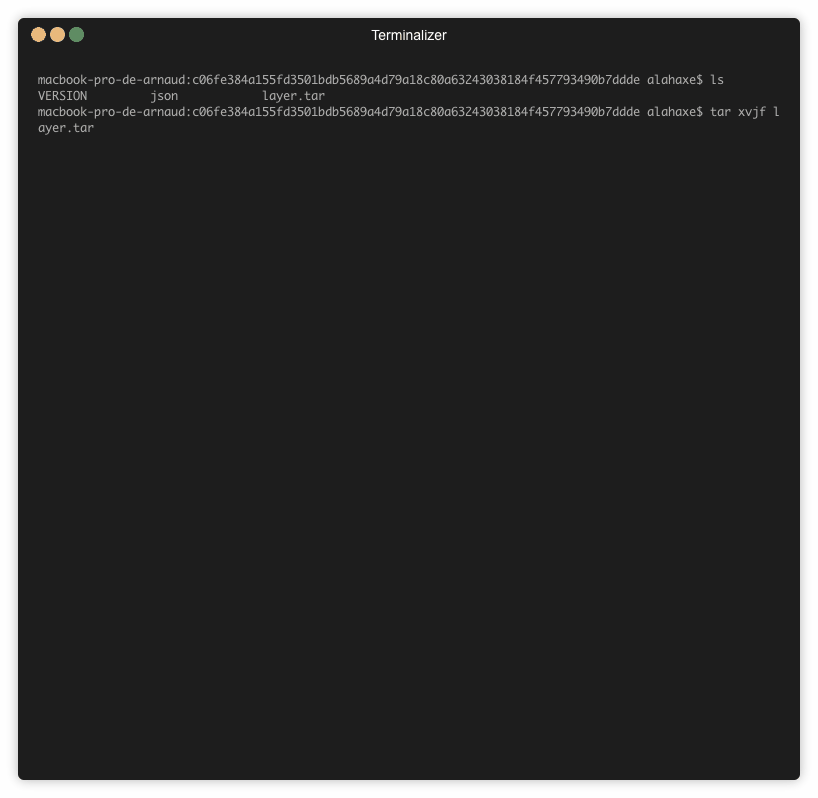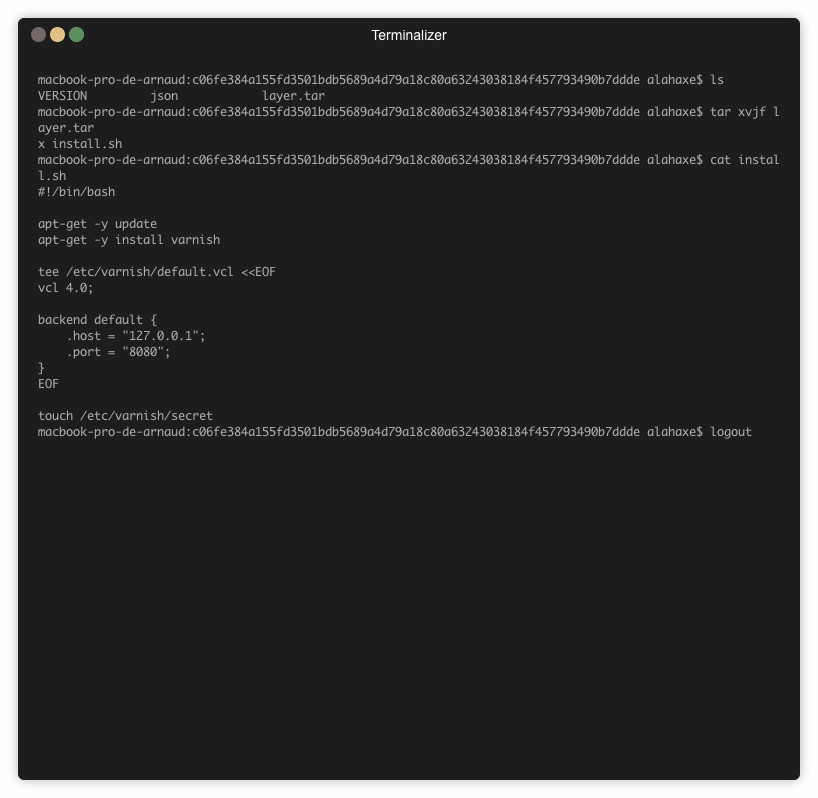
Pour le fichier install.sh il ne va malheureusement pas être possible de l’afficher car il est supprimé pendant le build. Le docker history de l’image ne me donne pas d’image Id correspondant à ce layer car je n’ai pas buildé l’image sur ma machine.
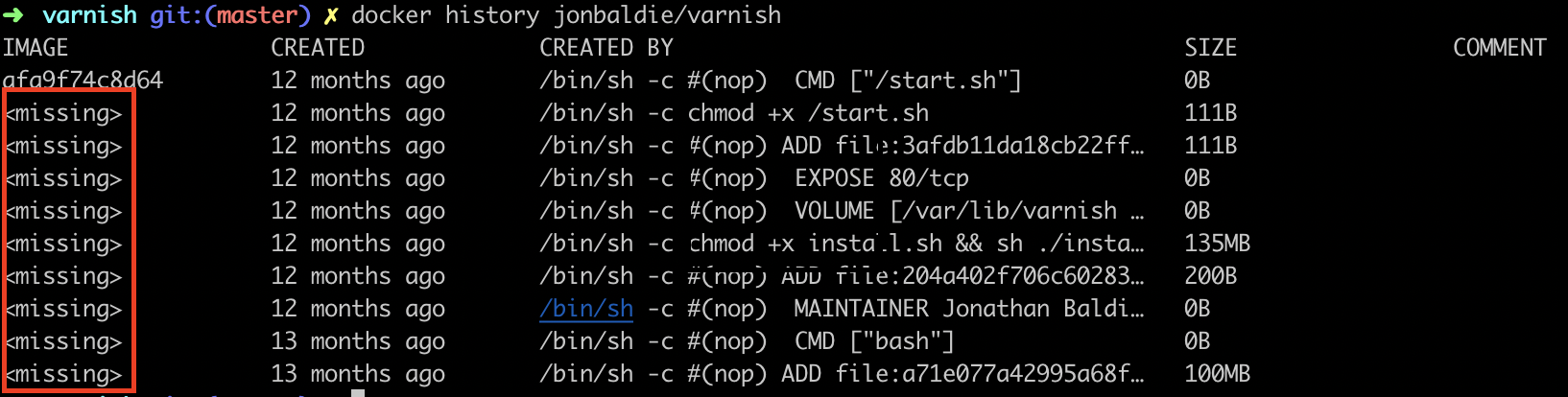
Il n’est pas possible de lancer un container sur une image qui contient le install.sh. Et c’est bien là le problème ! C’est une boîte noire.
Pour arriver à consulter ce fichier il va falloir exporter l’image et naviguer dans les layers « à la main ».
Pour voir le fichier on va récupérer le tar id du layer qui nous intéresse via Dive :
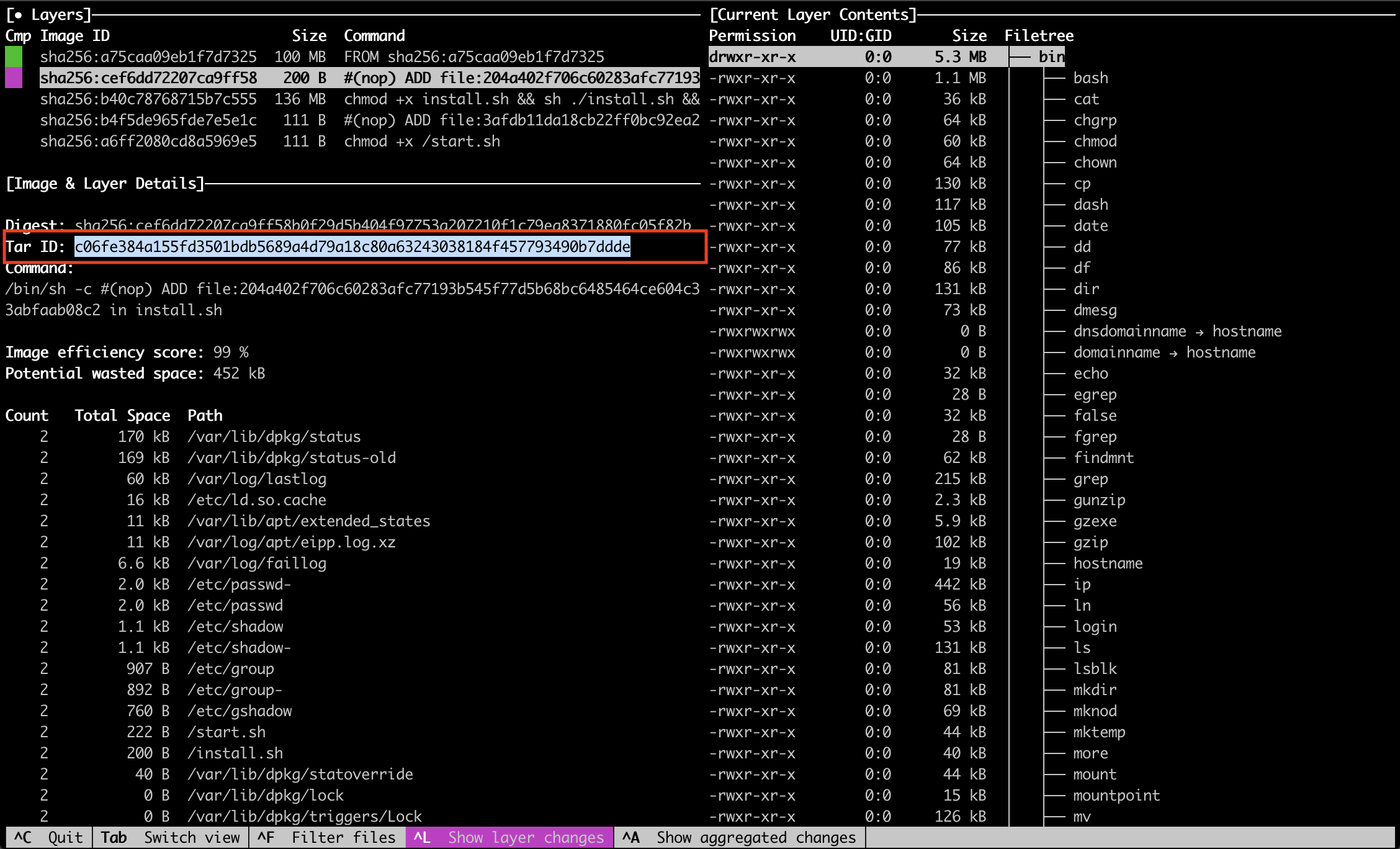
On sait donc maintenant qu’il faut regarder le contenu du tar « c06fe384a155fd3501bdb5689a4d79a18c80a63243038184f457793490b7ddde » pour trouver mon fichier install.sh.
Vérifier l’image de base
Dans notre cas l’image est construite à partir d’une debian officielle. Mais comment s’en assurer ? Est-ce que cette debian est à jour ?
Dans un premier temps on va chercher la version de debian installée :
➜ varnish docker run --rm jonbaldie/varnish cat /etc/os-release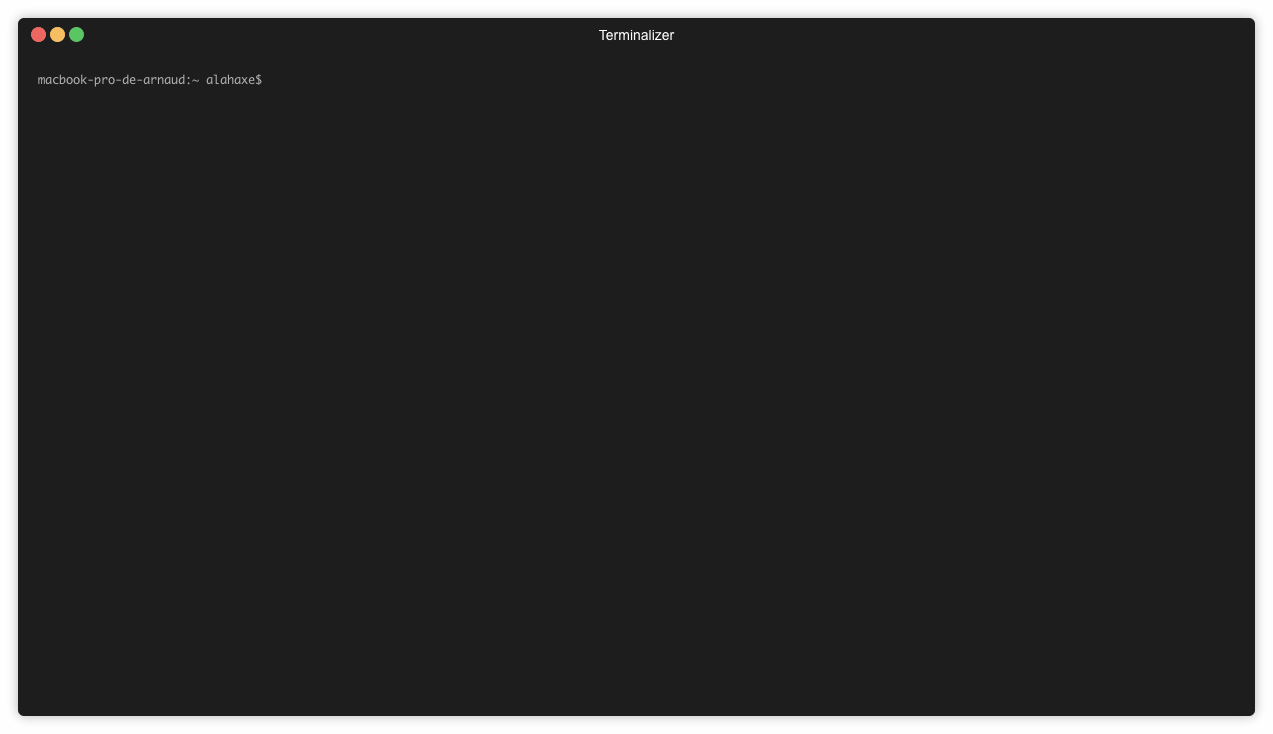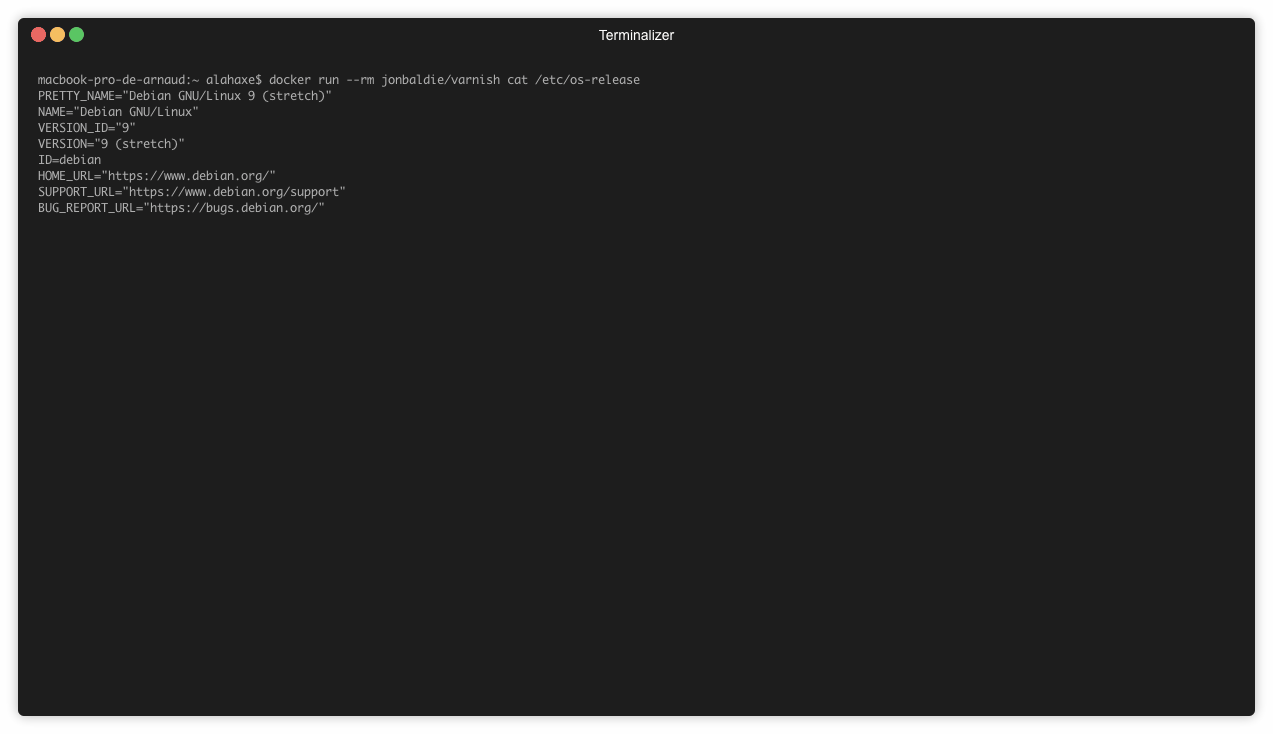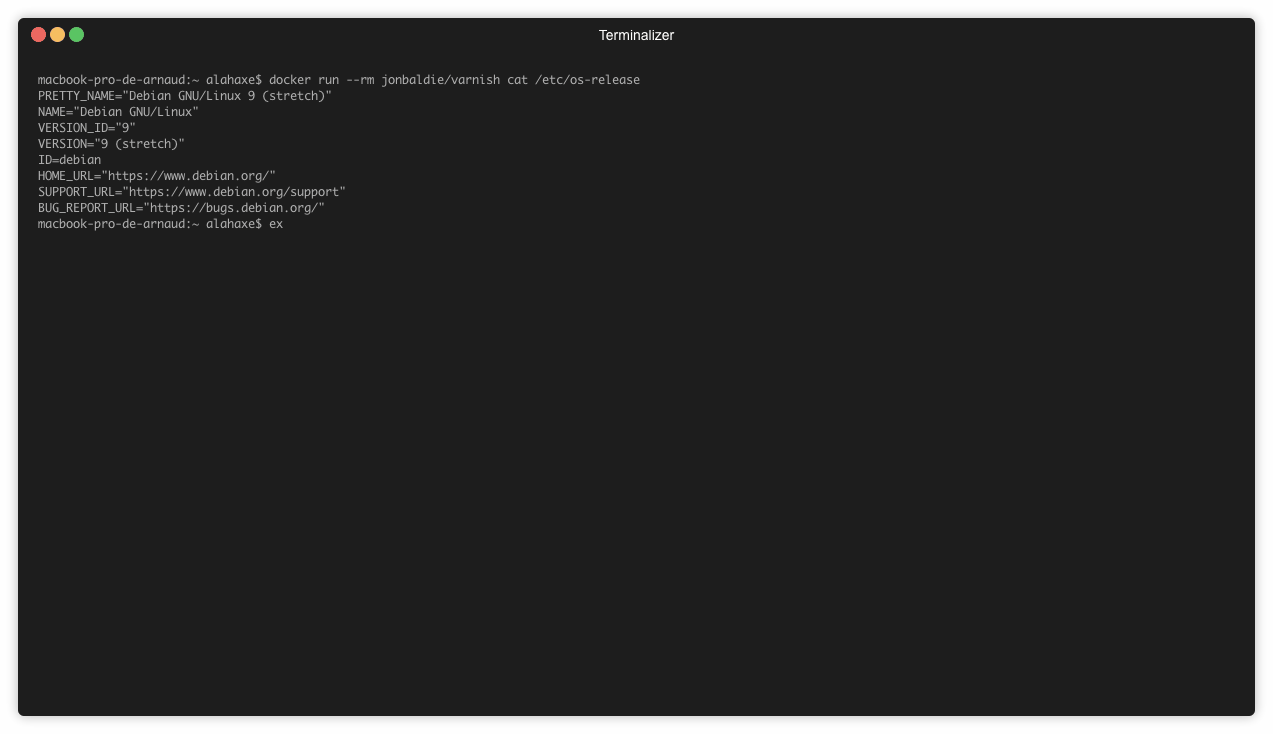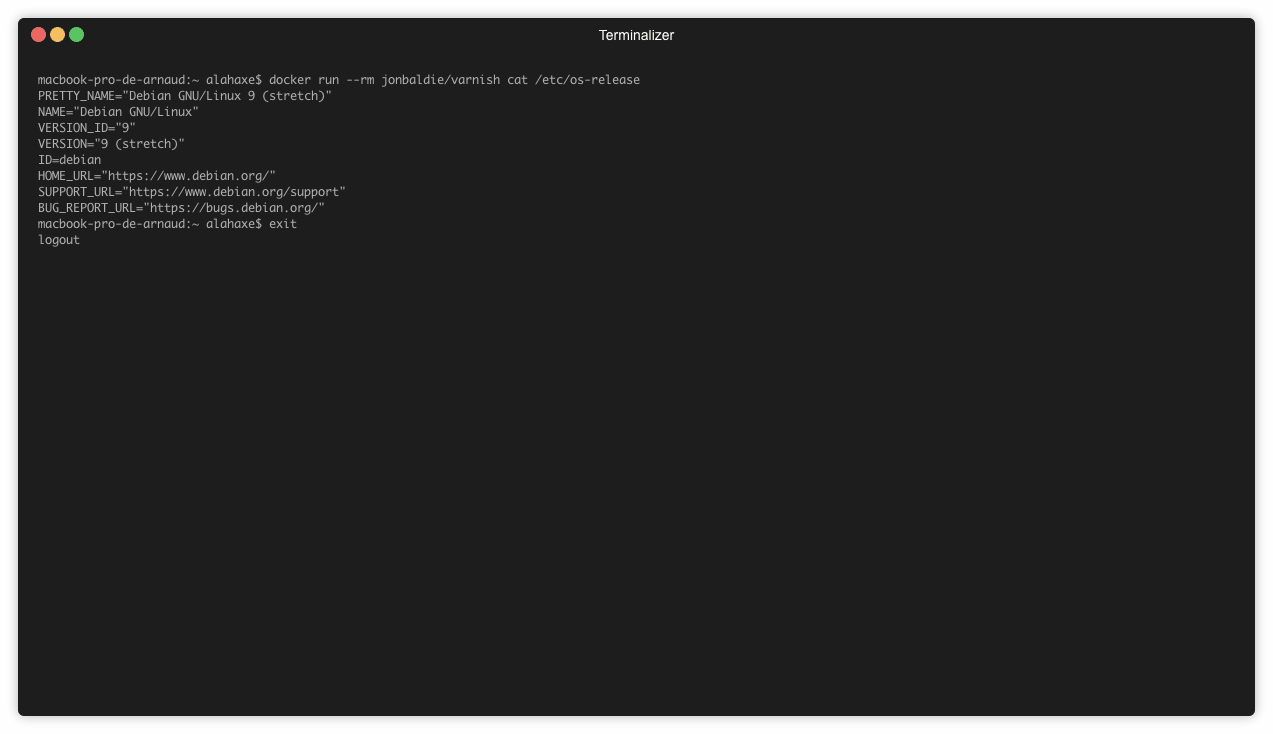
Malheureusement je ne sais pas comment vérifier que cette debian est bien une version officielle. Je ne peux pas non plus m’assurer que les mises à jour de sécurité sont faites.
Le seul indicateur de qualité à ce niveau est de regarder les builds. Cette image est buildée automatiquement sur la Docker Cloud’s infrastructure. Ce point est primordial dans le choix d’une image non officielle car cela nous donne l’assurance que le docker file affiché est bien celui qui est utilisé pour le build.
Sur le dernier build par exemple nous avons plusieurs informations à disposition :
Building in Docker Cloud's infrastructure...
Cloning into '.'...
KernelVersion: 4.4.0-93-generic
Arch: amd64
BuildTime: 2017-08-17T22:50:04.828747906+00:00
ApiVersion: 1.30
Version: 17.06.1-ce
MinAPIVersion: 1.12
GitCommit: 874a737
Os: linux
GoVersion: go1.8.3
Starting build of index.docker.io/jonbaldie/varnish:latest...
Step 1/9 : FROM debian
---> 874e27b628fd
Step 2/9 : MAINTAINER Jonathan Baldie "[email protected]"
---> Running in 3691027bb23a
---> 6e1fd6e2af21
Removing intermediate container 3691027bb23a
Step 3/9 : ADD install.sh install.sh
---> 2d9d517255c6
Removing intermediate container 1882f5bc4a22
Step 4/9 : RUN chmod +x install.sh && sh ./install.sh && rm install.sh
---> Running in 77dd464fc5be
Ign:1 http://deb.debian.org/debian stretch InRelease
//...
Get:8 http://security.debian.org stretch/updates/main amd64 Packages [227 kB]
Fetched 10.0 MB in 4s (2119 kB/s)
Reading package lists...
Reading package lists...
Building dependency tree...
Reading state information...
The following additional packages will be installed:
binutils cpp cpp-6 gcc gcc-6 libasan3 libatomic1 libbsd0 libc-dev-bin
libc6-dev libcc1-0 libcilkrts5 libedit2 libgcc-6-dev libgmp10 libgomp1
libgpm2 libisl15 libitm1 libjemalloc1 liblsan0 libmpc3 libmpfr4 libmpx2
libncurses5 libquadmath0 libtsan0 libubsan0 libvarnishapi1 linux-libc-dev
manpages manpages-dev
Suggested packages:
binutils-doc cpp-doc gcc-6-locales gcc-multilib make autoconf automake
libtool flex bison gdb gcc-doc gcc-6-multilib gcc-6-doc libgcc1-dbg
libgomp1-dbg libitm1-dbg libatomic1-dbg libasan3-dbg liblsan0-dbg
libtsan0-dbg libubsan0-dbg libcilkrts5-dbg libmpx2-dbg libquadmath0-dbg
glibc-doc gpm man-browser varnish-doc
The following NEW packages will be installed:
binutils cpp cpp-6 gcc gcc-6 libasan3 libatomic1 libbsd0 libc-dev-bin
libc6-dev libcc1-0 libcilkrts5 libedit2 libgcc-6-dev libgmp10 libgomp1
libgpm2 libisl15 libitm1 libjemalloc1 liblsan0 libmpc3 libmpfr4 libmpx2
libncurses5 libquadmath0 libtsan0 libubsan0 libvarnishapi1 linux-libc-dev
manpages manpages-dev varnish
0 upgraded, 33 newly installed, 0 to remove and 1 not upgraded.
Need to get 30.5 MB of archives.
After this operation, 123 MB of additional disk space will be used.
Get:1 http://deb.debian.org/debian stretch/main amd64 libbsd0 amd64 0.8.3-1 [83.0 kB]
//...
Get:33 http://deb.debian.org/debian stretch/main amd64 varnish amd64 5.0.0-7+deb9u1 [690 kB]
[91mdebconf: delaying package configuration, since apt-utils is not installed
[0m
Fetched 30.5 MB in 1s (18.9 MB/s)
Selecting previously unselected package libbsd0:amd64.
Preparing to unpack .../00-libbsd0_0.8.3-1_amd64.deb ...
//...
Setting up varnish (5.0.0-7+deb9u1) ...
Processing triggers for libc-bin (2.24-11+deb9u1) ...
vcl 4.0;
backend default {
.host = "127.0.0.1";
.port = "8080";
}
---> 0953378c3b8d
Removing intermediate container 77dd464fc5be
Step 5/9 : VOLUME /var/lib/varnish /etc/varnish
---> Running in c56c31df17fb
---> e7f1ae57b0f0
Removing intermediate container c56c31df17fb
Step 6/9 : EXPOSE 80
---> Running in e1f015e6366e
---> 6000a2d9d149
Removing intermediate container e1f015e6366e
Step 7/9 : ADD start.sh /start.sh
---> 085cec1148a7
Removing intermediate container 73e8ab753261
Step 8/9 : RUN chmod +x /start.sh
---> Running in 8ab33da3607a
---> 06f67d6546ac
Removing intermediate container 8ab33da3607a
Step 9/9 : CMD /start.sh
---> Running in 3910129787df
---> afa9f74c8d64
Removing intermediate container 3910129787df
Successfully built afa9f74c8d64
Successfully tagged jonbaldie/varnish:latest
Pushing index.docker.io/jonbaldie/varnish:latest...
Done!
Build finishedPremière information, l’image est bien construite à partir de l’image debian officielle comme on peut le voir à la step 1: « Step 1/9 : FROM debian ».
Seconde information, l’image a été buildée le 17 Août 2017. Toutes les failles détectées depuis cette date sur varnish et debian stretch ne sont donc pas patchées.
Pour les images qui ne sont pas buildées automatiquement sur la plateforme je ne sais pas si c’est possible de vérifier l’intégrité de l’image de base. J’ai tenté plusieurs approches mais comme l’image utilise une « latest » et qu’elle a été remplacée par une nouvelle version je ne vois pas comment faire pour retrouver mon layer. Si vous avez une solution, je suis preneur.
Builder ses propres images
La solution qui présente le moins de risques est de builder soi-même ses images à partir des Dockerfiles mis à disposition par les contributeurs. De cette manière on peut faire une revue complète du code et des dépendances. En buildant moi-même mon image je pourrais avoir une version plus à jour de debian et de varnish.
➜ git clone https://github.com/jonbaldie/varnish.git
➜ cd varnish
➜ docker build -t alahaxe/varnish:latest .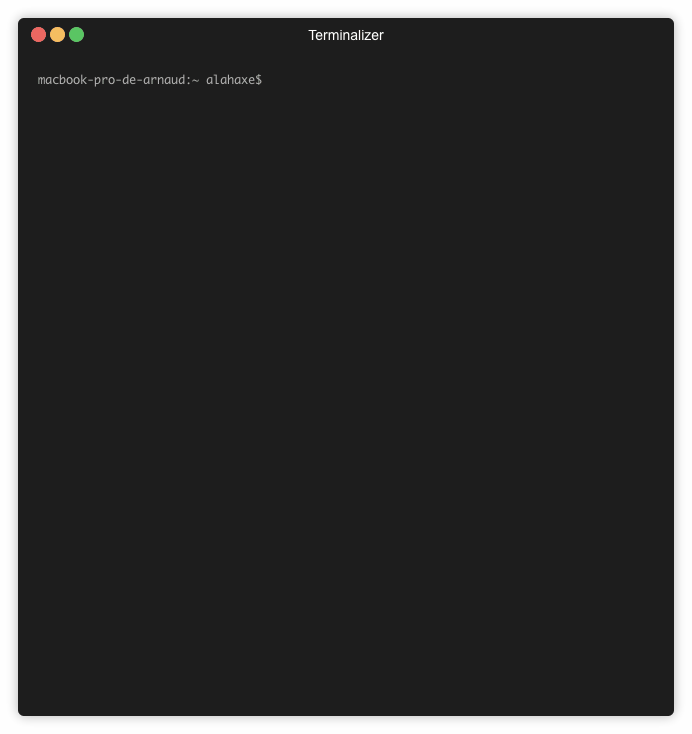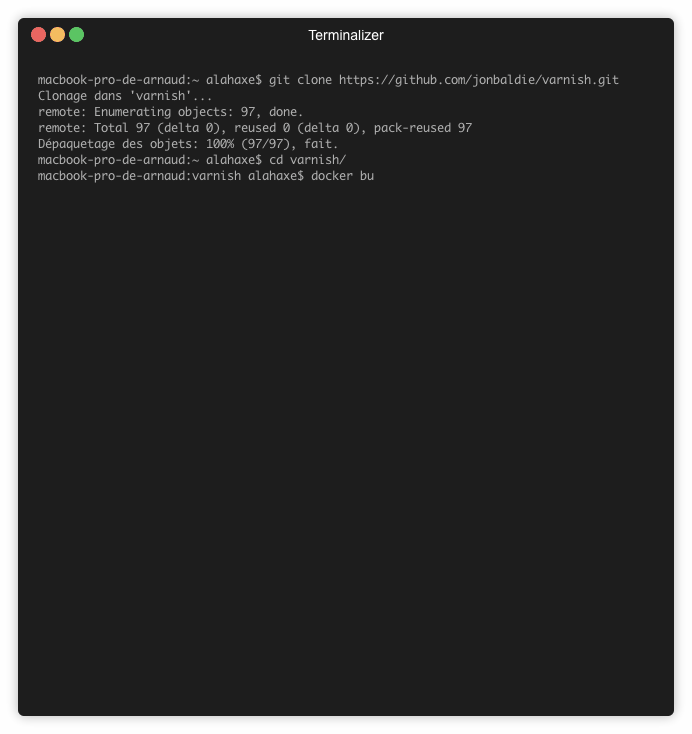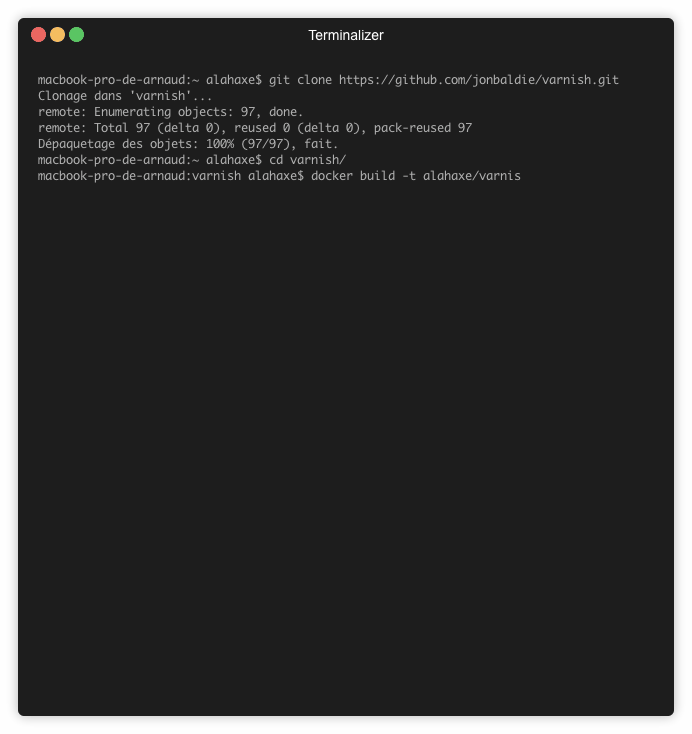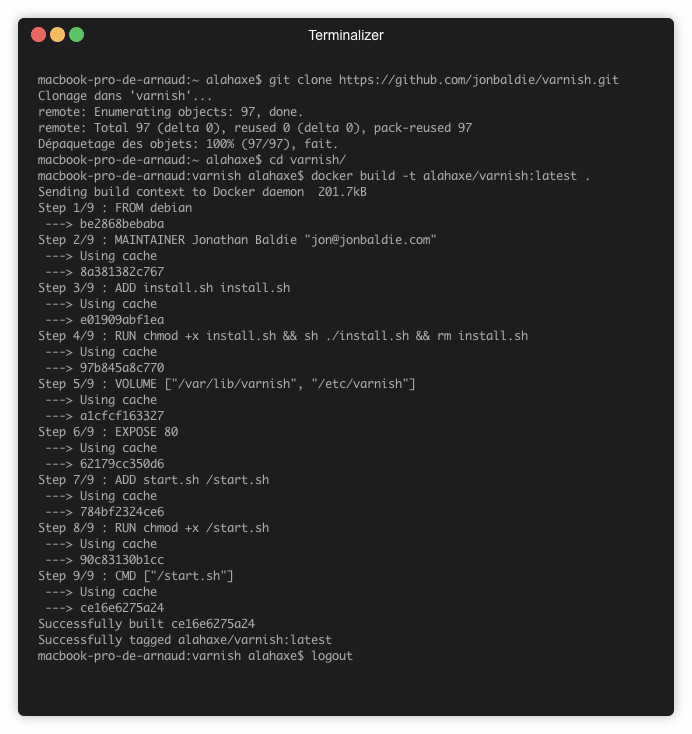
Conclusion
Il faut absolument se méfier des images mises à disposition sur le Dockerhub. Avant d’utiliser une image on doit se poser au minimum les questions suivantes :
- Est-ce que l’image est officielle ou buildée automatiquement ?
- Si non, est-ce que les sources sont disponibles ?
- Si oui, est-ce que le dockerfile présenté est vraiment celui qui a servi à builder l’image ?
- Si non, est-ce que les sources sont disponibles ?
- De quand date la dernière build ?
Au moindre doute il est préférable de builder sa propre version de l’image ou d’en utiliser une autre.