
Dans cet article, nous allons parler Mojitos, machine learning et PHP, trois sujets que l’on mélange assez rarement, mais qui dans le cas du site Cocktailand sont rassemblés.

Use case
Je souhaite afficher la recette de cocktail qui ressemble le plus à celle que le visiteur est en train de lire. Comme je suis finalement quelqu’un d’assez fainéant, je n’ai pas envie de maintenir des listes de cocktails associés manuellement. Il faut donc trouver un moyen de calculer automatiquement cette liste pour les quelques 600 recettes et que cette liste soit mise à jour automatiquement pour intégrer les nouvelles recettes.
Données à disposition:
- Les ingrédients de la recette, avec les volumes pour chacun
- Est-ce que le cocktail est alcoolisé ou non
- La catégorie du cocktail
- Le nombre de vues de la recette de cocktail
KNearestNeighbors
Afin de résoudre ce problème, je vais utiliser un algorithme de classification nommé KNearestNeighbors mis à disposition en PHP via la libraire php-ml avec une méthode de calcul de distance custom entre les cocktails.
Cet algo, aussi appelé le K-NN, permet de classifier des objets en fonction de la classe des autres objets déjà classifiés à proximité. La proximité est calculée par une méthode du type Euclidienne, Hamming, Manhattan ou encore selon des règles spécifiques au domaine. Il suffit que la méthode soit idempotente et qu’elle retourne une valeur numérique pour qu’elle soit utilisable.
Le K de cet algorithme est la valeur de validation croisée qui va permettre de choisir la classe à associer à l’objet.
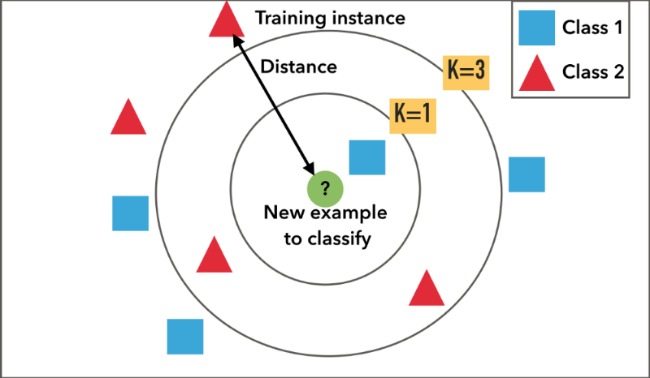
Pour déterminer la classe de l’objet vert, on va regarder la classe des objets à proximité, selon la valeur de K.
Pour K=1 on va choisir la classe de l’élément le plus proche.
Pour K=n on va choisir la classe la plus représentée dans les éléments sélectionnés.
Méthodologie
Plusieurs étapes sont nécessaires pour utiliser cet algorithme sur un jeu de données :
- Normaliser les données pour construire notre modèle
- Construire le modèle
- Ecrire ou Choisir la méthode de calcul de distance
- Choisir notre K
- Utiliser le modèle pour faire de la prédiction
Normalisation des données
Cette étape va nous permettre de supprimer tout ce qui n’apporte pas de sens et transformer toutes les données qui composent un cocktail par des entiers. Pour mon modèle j’ai choisi de prendre en compte seulement les informations suivantes :
- Les ingrédients, en les représentant par leur id en base
- Le fait de savoir si le cocktail est alcoolisé ou non (0 ou 1)
Afin de limiter le bruit dans le modèle j’ai décidé de supprimer des ingrédients non discriminants comme l’eau, la glace et le sucre. L’idée est de ne pas laisser l’algorithme penser que deux cocktails sont similaires car on y met des glaçons. Une fois que j’ai ma liste d’ingrédients nettoyée, il faut normaliser les données afin de les transformer en tableau d’entier. C’est un prérequis de l’implémentation de php-ml.
Pour le moment, je vais mettre de côté la popularité du cocktail, mais je pourrais la segmenter en 3 groupes peu/ moyen/ très populaire. Pour ce classement, il faudrait simplement ramener le nombre de vues en un nombre de 1 à 3 (via les percentiles 25% et 75% par exemple) et de valoriser cette information au moment du calcul de distance.
Construire le modèle
Pour cette étape, je vais créer une matrice qui aura en nombre de lignes le nombre de cocktails du site et en nombre de colonnes le nombre maximum d’ingrédients plus un d’un cocktail sur le site. Cette étape peut être particulièrement coûteuse en mémoire.
Une ligne de la matrice contient donc en premier index 0 ou 1 selon si le cocktail contient de l’alcool et dans les colonnes suivantes les ids des ingrédients qui composent le cocktail. Les cellules vides de la matrice sont remplies par des 0 car il est nécessaire d’avoir des lignes de la même taille.
Sur l’implémentation proposée, il y a un second tableau qui doit contenir les labels (classes) associées aux différentes lignes. J’ai choisi d’y mettre l’id (casté en string) du cocktail.
Comme cette étape est un peu coûteuse, je serialize la matrice dans un fichier pour pouvoir m’en resservir au besoin.
Une fois la matrice générée nous pouvons entrainer notre modèle (avec la méthode « train » ou « fit » selon vos librairies) sur notre jeu de données.
Choisir notre K
Dans notre cas, chaque élément est porteur de sa propre classe. C’est un cas un peu particulier, mais qui ne pose pas spécialement de problème pour cet algo. Mais au vu du fonctionnement de la valeur de validation croisée, il faut que nous utilisions un K à 1. Une valeur supérieure n’aurait pas de sens, car nous aurions autant d’ex aequo que la valeur de K.
Ecrire la méthode de calcul de distance
Comme notre modèle est assez spécifique et que faire une ACP sur notre matrice n’aurait pas de sens, j’ai pris le parti d’écrire ma propre méthode de calcul de distance.
La méthode de calcul de distance prend en paramètre deux lignes de la matrice et doit retourner un float (la distance). Libre à nous de réfléchir à la meilleure façon de faire ce calcul ou d’utiliser une méthode disponible de base.
Voici mon implémentation :
On remarque que j’utilise des nombres magiques dans mon algorithme (2, 3, 5, 10) . Les valeurs me permettent de donner plus ou moins d’importance à un type de différence. Une grande discrimination est donnée pour une différence au niveau de la présence ou non d’alcool.
Exemple sur un jeu de données
[table id=2 /]
Voici la matrice qui est générée pour ce jeu de données avec sur la droite le nom des cocktails associés à chaque ligne:
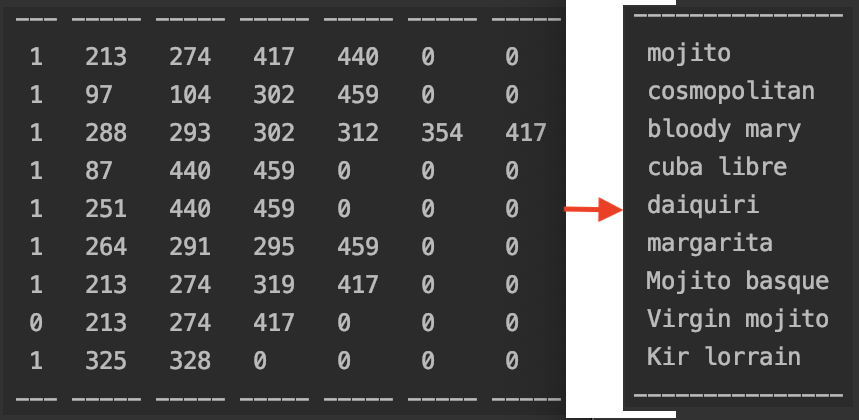
Dans les colonnes du premier tableau, nous avons dans la première colonne la présence ou non d’alcool et dans les autres les ids des ingrédients qui composent la recette.
Nous allons maintenant utiliser notre modèle pour trouver le cocktail le plus proche du Mojito.
La sortie en console est la suivante:

C’est bien le résultat que l’on aurait imaginé, mais pour comprendre pourquoi ce résultat, il faut s’intéresser aux distances que l’algo a calculé pour chaque cocktail. Voici ce que l’on obtient :
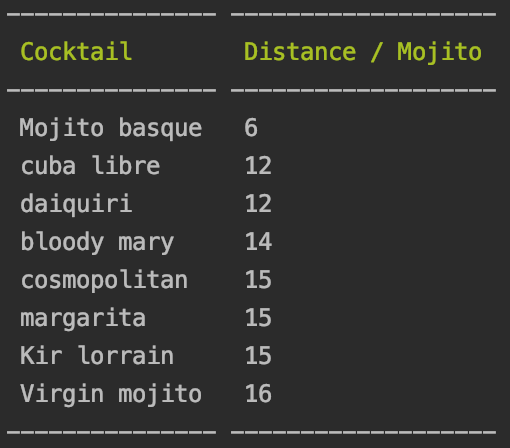
On remarque que la discrimination sur l’absence d’alcool est forte. C’est une volonté de ma part pour éviter, si possible, de proposer des recettes avec alcool pour un cocktail sans alcool.
Sur le site le volume de données à traiter est beaucoup plus gros évidement mais le principe reste le même.
Voici le résultat en production sur la recette du mojito:

Pour arriver à ce résultat sur un grand jeu de données, je répète l’algorithme n fois en retirant du modèle les recettes déjà sélectionnées.
Automatisation
La génération de la matrice est assez coûteuse, il faut quasiment dumper toute la base de données et travailler dessus. Il n’est donc pas possible de le faire « à la demande ». J’ai pris le parti de faire une commande Symfony qui est exécutée plusieurs fois par jour pour mettre à jour les données normalisées dans un fichier plat. Et pour la partie entraînement et prédiction, le résultat est mis en cache HTTP à l’aide d’un ESI pour 24h. Cela signifie qu’un nouveau cocktail ne remontera dans les suggestions que maximum 24h après son ajout à moins de flusher le cache varnish manuellement. Dans le cadre de Cocktailand cette latence est tout à fait acceptable.
Laisser un commentaire