Si vous n’avez pas de compte payant sur docker hub mais que vous ne voulez pas publier publiquement une image docker il va falloir trouver des solutions pour pouvoir héberger vos images docker. Par exemple en montant un registry docker privé pour héberger vos images docker.
Dans cet article nous allons voir comment monter un registry docker et comment y accéder en HTTPs sans avoir à déployer de certificat.
Pour cet exemple je vais utiliser un petit serveur START1-S chez scaleway à moins de 2 euros par mois.
Je préfère avoir de toutes petites instances de serveurs, plutôt que tout avoir sur la même machine. Si jamais une des machines se fait pirater, ou si elle a une panne matérielle, il n’y aura qu’un de mes projets perso qui sera hors ligne.
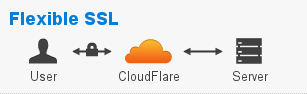
Plusieurs méthodes sont possibles, de la plus simple à la plus complexe. Vous pourrez trouver des tutos pour le faire via du let’s encrypt mais je suis parti sur quelque chose de plus simple. Comme je gère mes DNS avec cloudflare je vais utiliser le SSL flexible.
Ce n’est pas un SSL de bout en bout mais c’est suffisant pour ce que je fais sur domaine lahaxe.fr. Il n’y a en effet aucune donnée critique qui transite dessus.
Créer un sous domaine
Dans le menu DNS il va falloir ajouter une entrée, par exemple dans mon cas « registry.lahaxe.fr« , et la faire pointer vers votre serveur.
Activer le SSL flexible dans cloudflare
Dans le menu Crypto il y a une section SSL. Dans le menu déroulant il faut sélectionner Flexible.
Encore une fois, c’est satisfaisant pour un projet perso, mais ça ne l’est pas pour de la vraie production.
Lancer le registry
Il existe une image officielle pour monter son propre registry. Elle est très sobrement nommé registry.
L’image expose le port 5000 mais on va le mapper sur le port 80 afin de profiter du SSL flexible de Cloudflare.
Vous pouvez vérifier le bon fonctionnement en consultant l’url https://registry.lahaxe.fr/v2/_catalog (dans mon cas).
A partir de ce moment vous avez un registry fonctionnel mais public. N’importe qui peut pousser et télécharger une image dessus. Nous verrons dans la section « sécuriser le registry » comment mettre en place la sécurité sur le registry.
Uploader une image
Maintenant que nous avons notre registry de disponible nous allons pouvoir lui pousser une image pour nous assurer que tout est bien configuré.
# pull d'une image sur le hub
docker pull alpine
# on re-tag l'image
docker image tag alpine registry.lahaxe.fr/alpine
# push de l'image sur notre registry
docker push registry.lahaxe.fr/alpine
Sécuriser le registry
Avoir un registry ouvert est une très mauvaise pratique. Afin de le sécuriser un minimum nous pouvons mettre en place deux sécurités de base.
Filtre par IP
L’idée est de donner les accès seulement à vos serveurs et aux personnes qui doivent interagir avec. Il va donc falloir sécuriser le port 80 de serveur (ou le 443 si vous faites du SSL de bout en bout).
De mon côté je vais utiliser les security policies de scaleway pour bloquer le port. Attention: Il faut bien penser à redémarrer le serveur après avoir changé les règles de firewall scaleway. Mais sinon vous pouvez mettre en place un filtrage via iptable ou via shorewall.
Mettre en place de l’authentification
Dans un premier temps il va falloir générer un fichier htpasswd avec le ou les logins et mots de passes.
Il suffit de dire à l’image docker de prendre ce fichier et d’activer l’authentification basique. Il est absolument nécessaire d’être en HTTPS pour cette authentification sinon le mot de passe passera en clair dans les trames HTTP.
# si vous avez un container qui tourne déjà
docker rm -f registry
docker run -d -p 80:5000
--restart=always
--name registry
-v `pwd`/auth:/auth
-e "REGISTRY_AUTH=htpasswd"
-e "REGISTRY_AUTH_HTPASSWD_REALM=Registry Realm"
-e REGISTRY_AUTH_HTPASSWD_PATH=/auth/htpasswd
-v /opt/docker-registry:/var/lib/registry
registry:2
Sur les pc « clients », votre desktop par exemple, il faudra faire un docker login pour pouvoir utiliser le registry.
docker login registry.lahaxe.fr
Je ne mets pas en place de system de backup sur le registry car je n’en ai pas spécialement le besoin. Je préfère stocker l’ensemble de mes dockerfiles afin de pouvoir les reconstruire en cas de besoin.
Mole est une application en ligne de commande qui permet de simplifier la création de tunnels SSH.
Il est parfois utile de monter un tunnel pour accéder à un service qui n’est pas ouvert sur le WEB. Par exemple si votre serveur MYSQL, n’est accessible que depuis votre serveur web ou votre serveur de backup. Ou encore pour contourner un firewall qui bloquerait un port en particulier.
Sur cet exemple le serveur bleu ne peut pas accéder au port 80 (application web) du serveur rouge car un firewall le bloque. Mais le port 22 (ssh) est accessible. Il est donc possible de créer un tunnel qui forward le port 80 sur serveur rouge sur le port 8080 du serveur bleu. Une fois le tunnel mis en place il sera possible d’accéder à l’application web du serveur rouge via l’url: http://blue:8080.
Installation
Deux méthodes d’installation sont possibles. Via le script d’installation ou via homebrew pour les utilisateurs de mac.
Pour se connecter à un serveur mysql qui n’est pas ouvert sur le web nous allons ouvrir un tunnel entre le port 3306 local du serveur et le port 3307 de mon mac :
Je peux maintenant me connecter au serveur mysql du serveur sur le port 3307 de ma machine :
➜ mysql connect -h 127.0.0.1 -P 3307 -uxxxxxxx -p
Gestion des alias
Le dernier point qui est bien pratique si vous avez à jongler avec plusieurs serveurs c’est la gestion des alias. Il est possible d’enregister des alias pour les tunnels que l’on a fréquemment à créer.
HypriotOs est une version de raspbian dans laquelle docker, et docker swarm sont pré installés. La particularité est que HypriotOs tourne sur des architectures ARM telles que les Raspberry, le Nvidia shield et quelques autres cartes comme les ODROID C2.
Dans cet article, nous allons voir comment monter un petit cluster swarm avec trois noeuds (1 manager et 2 workers). Une fois la partie serveur montée, nous ferons tourner des services dessus à la fois en lignes de commandes et via une interface graphique.
Swarm
Swarm est l’orchestrateur historiquement intégré dans docker. Il permet de distribuer automatiquement les containers sur l’un ou l’autre des noeuds du cluster en fonction de l’indisponibilité ou de la charge d’un noeud. Docker inc a été testé pour scal
ler jusqu’à 1 000 nœuds et 50 000 conteneurs sans dégradation de performance. A mon avis nous allons avoir du mal à faire tourner autant de conteneurs sur nos Raspberry.
Il existe deux types de noeuds, les managers et les workers. Pour faire simple, les managers peuvent administrer ce qui tourne sur le cluster et répartir le travail sur les workers tandis que les workers sont de simples exécutants qui lancent des containers.
De base, le cluster va faire du mesh routing. Cela signifie, par exemple, que si vous lancez un serveur web sur le port 80 quelque part sur votre cluster, vous pourrez y accéder en attaquant n’importe quelle machine (worker ou manager) qui compose le cluster. Swarm va aussi nous proposer un système de load balancing afin de pouvoir distribuer la charge entre différentes instances d’un service.
Pour les utilisateurs de Linux et MacOs il existe un outil proposé par la communauté de Hypriot pour flasher les cartes. Malheureusement, pour les utilisateurs de Windows, les choses sont un peu plus compliquées.
Pour linux et mac
Hypriot flash est un utilitaire en lignes de commandes qui va s’occuper de tout, de la décompression de l’image à l’installation sur la carte SIM. Pour l’installation, tout est précisé dans le readme du dépôt.
➜ cat ../Downloads/hypriotos-rpi-v1.9.0.img.zip.sha256
be21a702887817d8c84c053f9ee4c54e04fd55e9fb9692edc3904801b14c33a8 hypriotos-rpi-v1.9.0.img.zip
# sur linux sha256sum / sur mac gsha256sum
➜ gsha256sum hypriotos-rpi-v1.9.0.img.zip
be21a702887817d8c84c053f9ee4c54e04fd55e9fb9692edc3904801b14c33a8 hypriotos-rpi-v1.9.0.img.zip
Votre mot de passe root vous sera demandé pendant l’installation de l’image sur la carte.
Vous devriez avoir une sortie console proche de celle ci:
flash --hostname worker-01 hypriotos-rpi-v1.9.0.img.zip
Using cached image /tmp/hypriotos-rpi-v1.9.0.img
Is /dev/disk2 correct? yes
Unmounting /dev/disk2 ...
Unmount of all volumes on disk2 was successful
Unmount of all volumes on disk2 was successful
Flashing /tmp/hypriotos-rpi-v1.9.0.img to /dev/rdisk2 ...
No 'pv' command found, so no progress available.
Press CTRL+T if you want to see the current info of dd command.
Password:
930+1 records in
930+1 records out
975765504 bytes transferred in 111.983538 secs (8713473 bytes/sec)
Mounting Disk
Mounting /dev/disk2 to customize...
Set hostname=worker-01
Unmounting /dev/disk2 ...
"disk2" ejected.
Finished.
Pour windows
Je n’ai jamais flashé mes cartes SD depuis Windows. Mais vous pourrez trouver une procédure sur le site de hypriot.
Dans le cas de Windows il faudra, si possible, éditer le fichier user-data (c’est un yml sans extension) à la racine de la carte SD pour changer le hostname qui est présent dedans. Il faudra en nommer un manager-01 et les deux autres worker-01 et worker-02 histoire de pouvoir suivre dans la suite de l’article.
Les branchements
Rien de bien complexe, les câbles ethernet dans les prises ethernets, les cables d’alimentation dans les micro usb et les cartes SD dans les slots prévus à cet effet. Et hop, le tour est joué. Vous devriez pouvoir détecter les machines sur votre réseau local.
Branchements raspberry pi pour un cluster swarm
Se connecter en SSH sur les différents noeuds
Sur mac, j’utilise l’application LanScan Pro depuis des années pour scanner mon réseau local.
Détection des machines du cluster swarm sur le réseau
J’ai bien mes trois Raspberry qui sont présents sur le réseau avec les ip 192.168.1.22, 23 et 24.
Pour se connecter en ssh sur les Raspberry il faut utiliser le login/ mot de passe par défaut de hypriotOS. A savoir pirate/ hypriot.
Première connexion SSH sur hypriot
A cette étape je vous conseille de faire les mises à jour avant d’aller plus loin. Ce serait dommage de faire toute sa configuration sur une version qui a des failles de sécu. De plus il est préférable d’avoir les versions de docker sur l’ensemble du cluster.
Le temps des mises à jour vous avez le temps d’aller prendre un café 😀
Les versions de docker
Création du cluster swarm
Creation du manager
Sur le rasp nommé manager-01 je vais créer le cluster swarm :
docker swarm init
La commande va créer le cluster, vous enregistrer en temps que leader et vous donner la commande pour ajouter des workers.
La création du cluster swarm
La liste des noeuds du cluster après création
Ajout des workers
Pour ajouter les workers on va utiliser la commande donnée au moment de la création du cluster en lançant sur les Raspberry worker-01 et worker-02.
Si vous avez perdu la commande vous pouvez la récupérer en vous connectant sur un manager et en exécutant la ligne de commande :
docker swarm join-token worker
Récupération de la commande pour joindre un cluster swarm
On va donc se connecter en ssh sur worker-01 et worker-02 et lancer la commande de join. Vous devriez avoir le résultat suivant :
Joindre un cluster swarm
Sur le manager on va voir apparaitre les noeuds en tant que worker si on utilise la commande docker node ls
La liste des noeuds d’un cluster swarm
Installation et utilisation de Portainer
Portainer est un outil de visualisation et d’administration et de visualisation open source pour docker. Il est assez intéressant dans notre cas car il va nous permettre de visualiser ce qu’il se passe sur l’ensemble de notre cluster depuis une interface WEB.
Installation de portainer
On va lancer un container Portainer sur le noeud manager-01.
Portainer est maintenant compatible avec notre architecture arm, il est donc possible d’utiliser l’image officielle.
Une fois le container lancé, vous pouvez vous rendre, via votre navigateur, sur le port 9000 de votre manager. Pour moi http://192.168.1.22:9000.
Vous allez être redirigé sur la page de création du compte administrateur. Il est préférable de ne pas conserver le nom d’utilisateur par défaut.
Installation portainer
La seconde étape de l’installation est le choix du type de connexion à docker. Nous allons choisir local car nous avons monté le socket docker lors de la création du container.
Installation portainer
Maintenant que Portainer est configuré nous allons pouvoir consulter notre cluster swarm, mais aussi lancer des services si nous le souhaitons.
On remarque déjà, que notre cluster est présent et que nos 3 noeuds sont bien détectés.
Cluster swarm dans portainer
En l’état notre cluster est composé de 12 coeurs et de 3 Go de ram.
Cluster visualizer
Lancer un service sur swarm
Pour lancer un service, il y a deux possibilité. Soit passer par portainer soit le faire en lignes de commandes. A vous de voir ce que vous préférez. J’ai préparé une petite image pour faire cette démo. Je m’excuse d’avance du poids de l’image (120Mo) pour faire un hello world…
J’ai buildé une image apache/ php qui affiche le hostname courant (celui du container). L’idée est de déployer un service sur le cluster et de voir comment il réagit et quel est le comportement que l’on obtient.
Déployer un service en lignes de commandes
Nous allons lancer une instance de notre image sur le cluster. Nous n’avons pas à nous soucier du choix de la machine sur laquelle l’application va tourner car le routing mesh nous permettra d’y accéder depuis n’importe quel noeud. Mais vous pouvez le savoir dans portainer en retournant sur la vue Cluster visualisation.
docker service create -p 80:80 --name hello-world docker.io/lahaxearnaud/swarm-hello-world
Création d’un service dans swarm
Il est possible de préciser beaucoup d’options pour limiter les ressources que le container pourra utiliser, la façon de vérifier que l’application est toujours up (health check)…
Déployer un service avec Portainer
Toutes les options que l’on peut donner via le cli sont disponibles via portainer pour la création de service. La mise en place de nouveau service est très simplifié grâce à l’interface graphique.
Creation d’un service dans portainer
Pour notre test nous n’avons pas besoin des configurations avancées.
Tester le load balancing
Nous avons maintenant un service qui tourne sur notre cluster et qui sert une « page » web contenant le nom du container qui le fait tourner. Pour tester le load balancing on fait une série d’appels et on va regarder si on obtient toujours le même nom de container.
for ((i=1;i<=10;i++)); do curl "http://192.168.1.22"; echo ""; done
Sans surprise pour le moment je vais obtenir 10 fois la même valeur, car nous n’avons qu’une instance qui tourne :
Dans un premier temps nous allons faire scaller notre application pour faire tourner 9 instances.
docker service scale hello-world=9
Vous pouvez aussi le faire via portainer en cliquant sur le service hello-world dans la section service et en modifiant la valeur dans le champs Replicas.
Scaller un service avec portainer
Il va falloir attendre un peu que l’image soit téléchargée sur les différents Raspberry et que les containers soient lancés. Mais une fois que tout est prêt, on va pouvoir relancer notre commande.
On se rend bien compte que la charge est distribuée entre les différentes machines. Sur les 10 hits on a touché les 9 instances.
Consulter les logs
Sur le manager vous pouvez faire un tail sur les logs d’un service via la commande docker service log -ft hello-world.
Visualisation des logs d’un service swarm
Dans portainer par contre il semblerait qu’il y ait un bug et qu’il ne remonte que les logs des instances présentes sur le manager.
Que mettre sur le cluster ?
Pour ma part, j’utilise swarm depuis au moins deux ans pour ma domotique. Comme je voulais jouer un peu avec l’IoT j’ai mis des capteurs un peu partout dans l’appartement (luminosité, température, mouvements, capteurs d’ouverture de porte et de fenêtre…) et chaque élément envoie des messages dans un rabbitmq. Mon cluster contient l’ensemble des consommateurs et l’application symfony qui sert l’interface graphique. Les consommateurs sont des workers symfony 4 qui utilisent le composant symfony messenger.
Avoir cette architecture en cluster permet de perdre ou d’ajouter un ou plusieurs serveurs sans devoir déplacer des applications à la main. Là où il faut être attentif c’est que swarm peut continuer de fonctionner en perdant un worker, mais la perte des managers est plus problématique. Il est préférable d’avoir plusieurs managers pour éviter que le cluster se retrouve sans manager en cas de panne. Un nombre impair de managers est préférable pour s’assurer que l’algorithme (Raft) arrive à élire un nouveau leader.
Retour d’expérience
La technologie est sympa et la fiabilité est au rendez-vous sur tout ce qui est worker et application web. Par contre, j’ai rencontré pas mal de problèmes en voulant mettre un rabbitmq, un elastic search ou encore un mysql dans le cluster. Après plusieurs crashes je les ai installés sur une machine séparée. Je ne sais pas à quel niveau se situe le problème, mais depuis que c’est sur un rasp séparé il n’y a plus de problèmes.
L’autre point est que j’ai une livebox à la maison, c’est elle qui me sert de DHCP (c’est dans ma todo de faire autrement). Elle a tendance à sortir du réseau les machines avec des ips fixes au bout de quelques jours. Je me suis retrouvé à plusieurs reprises avec un cluster qui était HS car toutes les machines étaient déconnectées.
Le fait d’être sur une architecture ARM nous empêche d’utiliser la plupart des images disponibles sur les hubs. Il faut donc passer du temps à faire ses propres images. Ce n’est pas forcement un mal !
Faq
Comment retirer proprement un noeud d’un cluster swarm ?
Si c’est un manager il faut se poser la question de promouvoir un worker en manager avant de commencer docker node promote worker-02 puis vous devez retirer le role manager au noeud à supprimer docker node demote manager-01. La seconde étape est de dire à l’orchestrateur d’enlever tout ce qui tourne sur le noeud docker node update --availability drain worker-01. Une fois qu’il n’y a plus rien sur le noeud on peut le sortir du cluster via la commande docker node rm worker-01. De cette manière il n’y aura pas d’interruption de service.
Comment supprimer le cluster swarm ?
Dans un premier temps il faut supprimer les services qui tournent dessus : docker service rm mon-service. Une fois que c’est fait vous pouvez supprimer les noeuds un à un via docker node rm -f node-name. Puis sur le manager faire un docker swarm leave -f.
Est-ce qu’il est possible de deployer une image locale ?
Non, il n’est pas possible de déployer une image qui n’est pas dans un registry. Mais vous pouvez monter votre propre registry et l’utiliser pour déployer vos images sur vos workers.
Est-il possible de déployer un fichier docker-compose sur swarm ?
Oui c’est possible via docker stack deploy
Est-ce que l’on peut monter des volumes dans les services ?
Oui vous pouvez, maintenant il y aura autant de volume que de noeuds sur lesquels tourneront vos applications.
Au travail nous avons pour politique de builder et de maintenir nos propres images docker. Mais pour un projet perso j’utilise des images docker publiques. Je m’efforce d’utiliser au maximum des images officielles mais certaines contributions de la communauté sont parfaites pour mes besoins. Le problème est de savoir avec certitude ce que contient un image. Une image téléchargée sur un hub est une boîte noire qu’il faut inspecter avant de l’utiliser.
Cas d’images corrompues
Il y a l’exemple de l’utilisateur docker123321 qui a diffusé 17 images contenant des backdoors sur dockerhub. Parmi les images il y a tomcat, mysql ou encore cron. Avec quasiment 5 millions de téléchargements docker123321 a réussi à miner plus de 500 Moneros en plus des portes d’entrées qu’il a créées sur le serveur.
Contenu d’une image docker
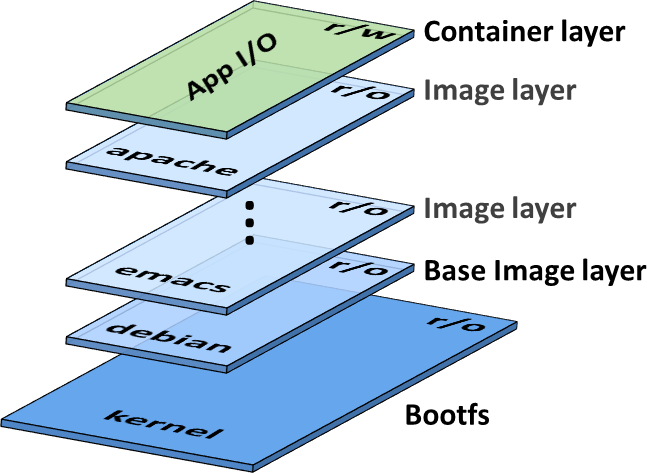
Une image docker est une succession de couches (layers) qui contiennent une liste de modifications du système de fichiers. On peut faire une analogie avec GIT où chaque layer serait un commit. Au moment de la création d’un container un layer est ajouté au-dessus de ceux de l’image. Mis à part ce layer « applicatif » les layers sont en read only.
Dive est un programme écrit en Go qui va vous permettre d’en savoir plus sur une image avant de l’utiliser. Il ne va pas permettre de s’assurer à 100% que l’image n’est pas corrompue mais il va pouvoir nous donner des information précieuses.
Pour l’installation je vous laisse vous référer au readme du projet.
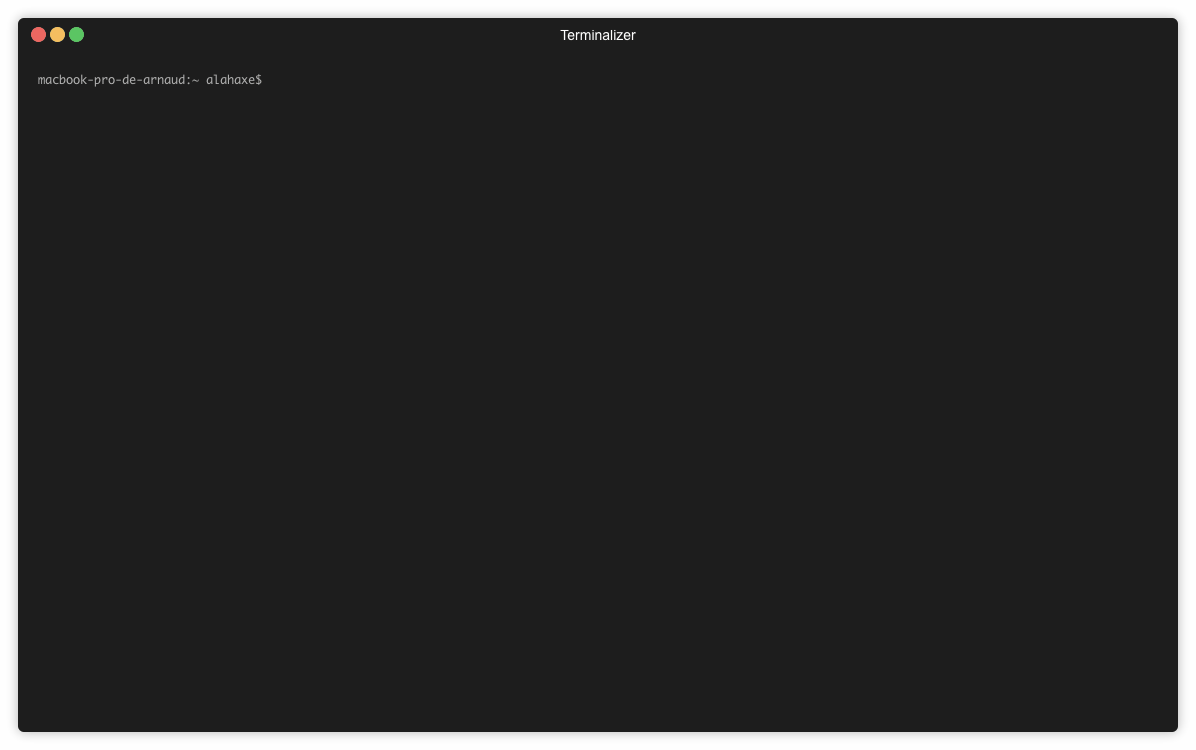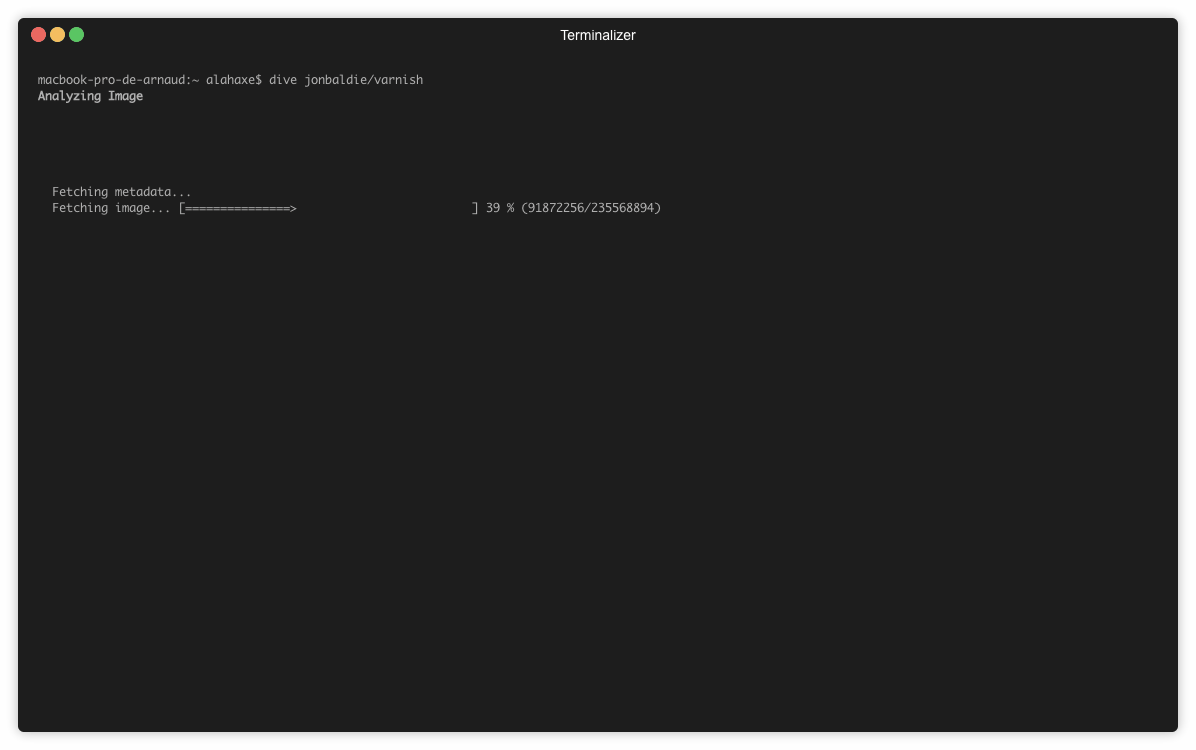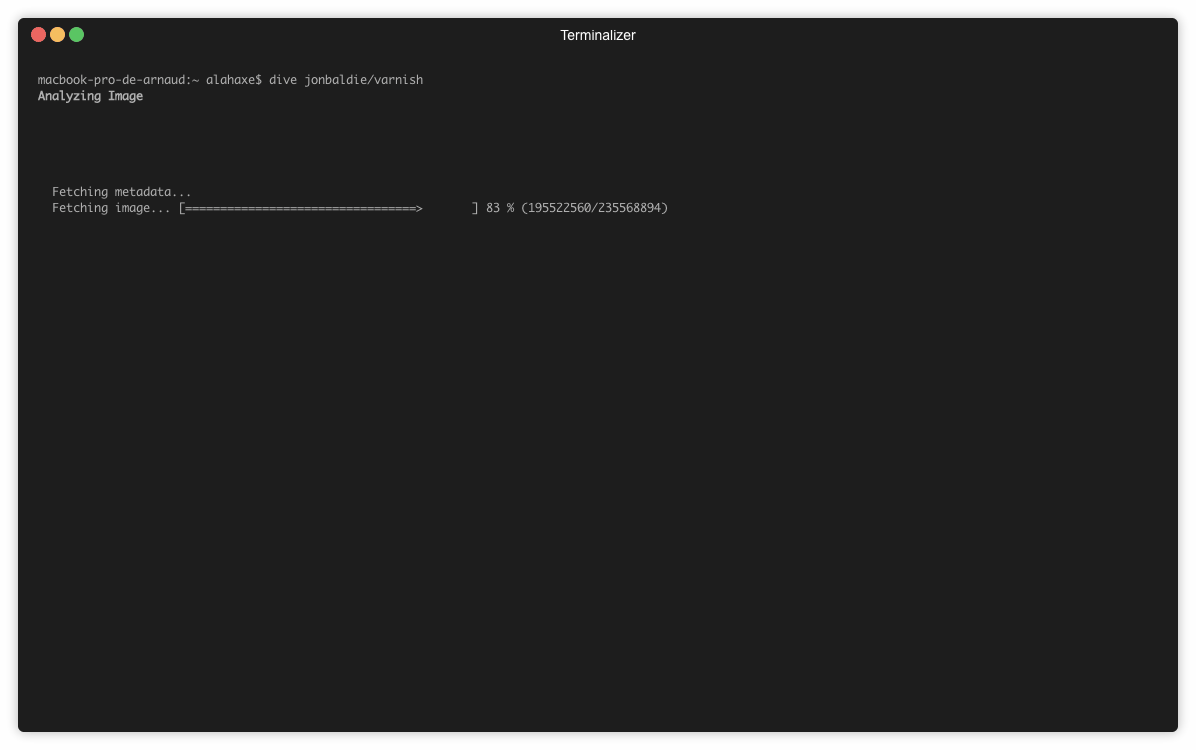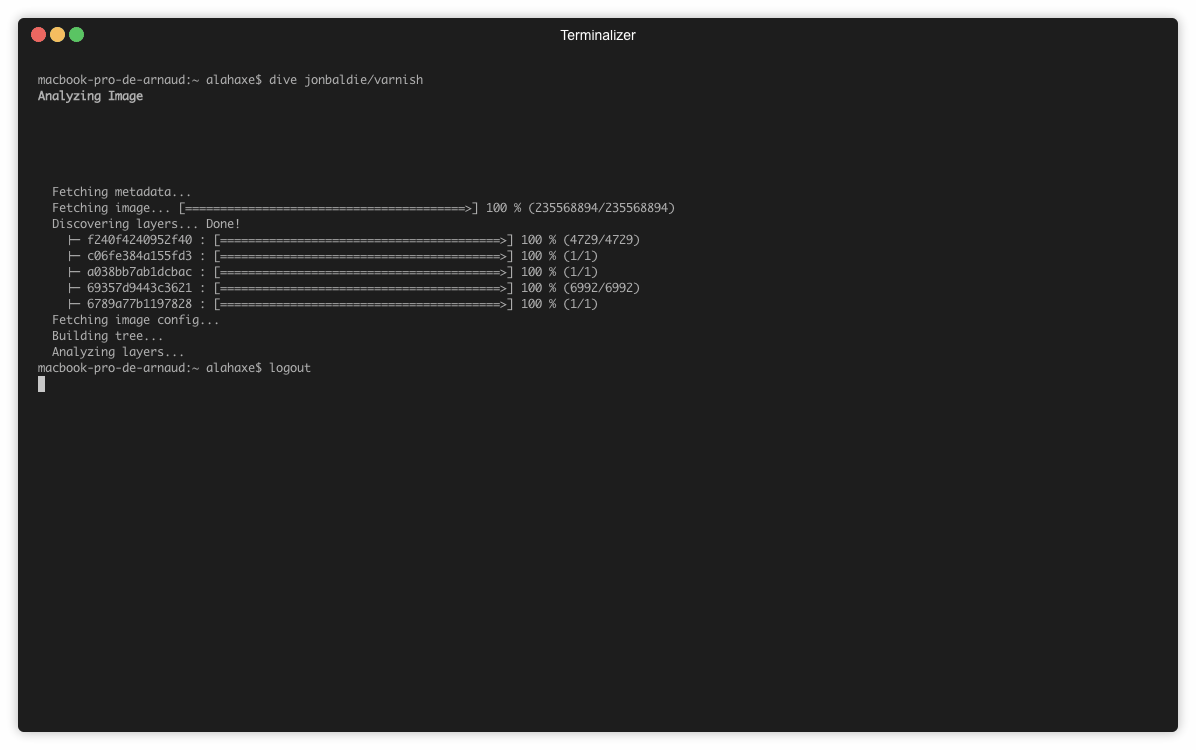
Voici un exemple d’utilisation sur l’image jonbaldie/varnish que j’utilise pour un projet perso.
➜ dive jonbaldie/varnish
Sur l’image on a 5 layers :
L’image de base
L’ajout d’un script d’installation (/install.sh)
Le résultat de l’execution du script d’install
L’ajout du script de boot (/start.sh)
Le chmod du script de boot
Vérifier les scripts présents dans l’image
Sur la base des informations données par Dive, il ne nous reste plus qu’à vérifier, si possible, le contenu des fichiers install.sh et start.sh
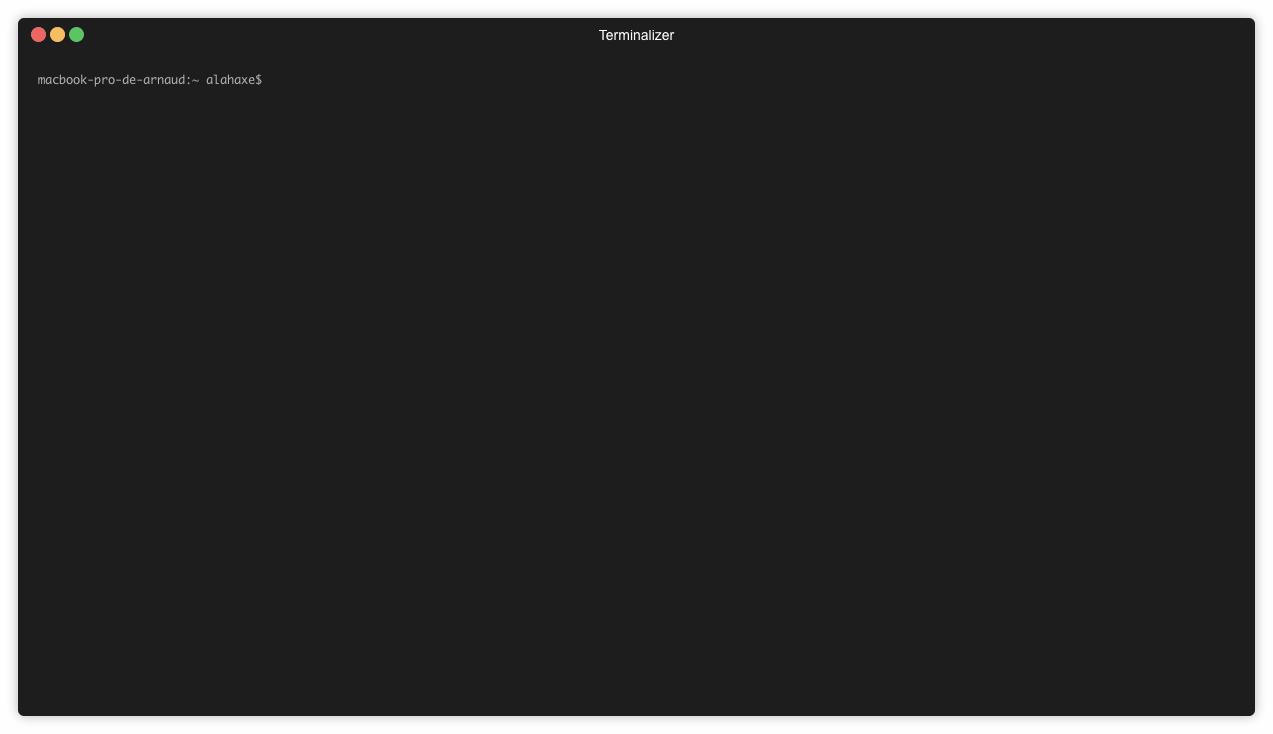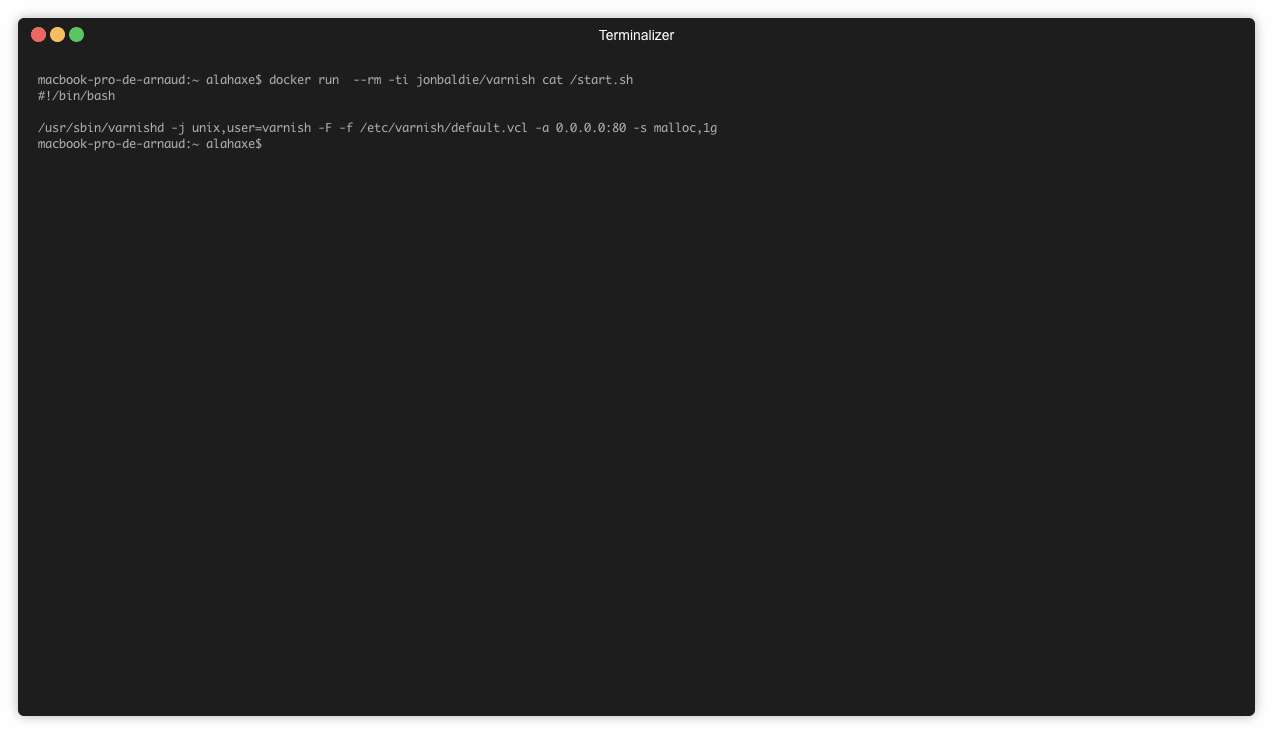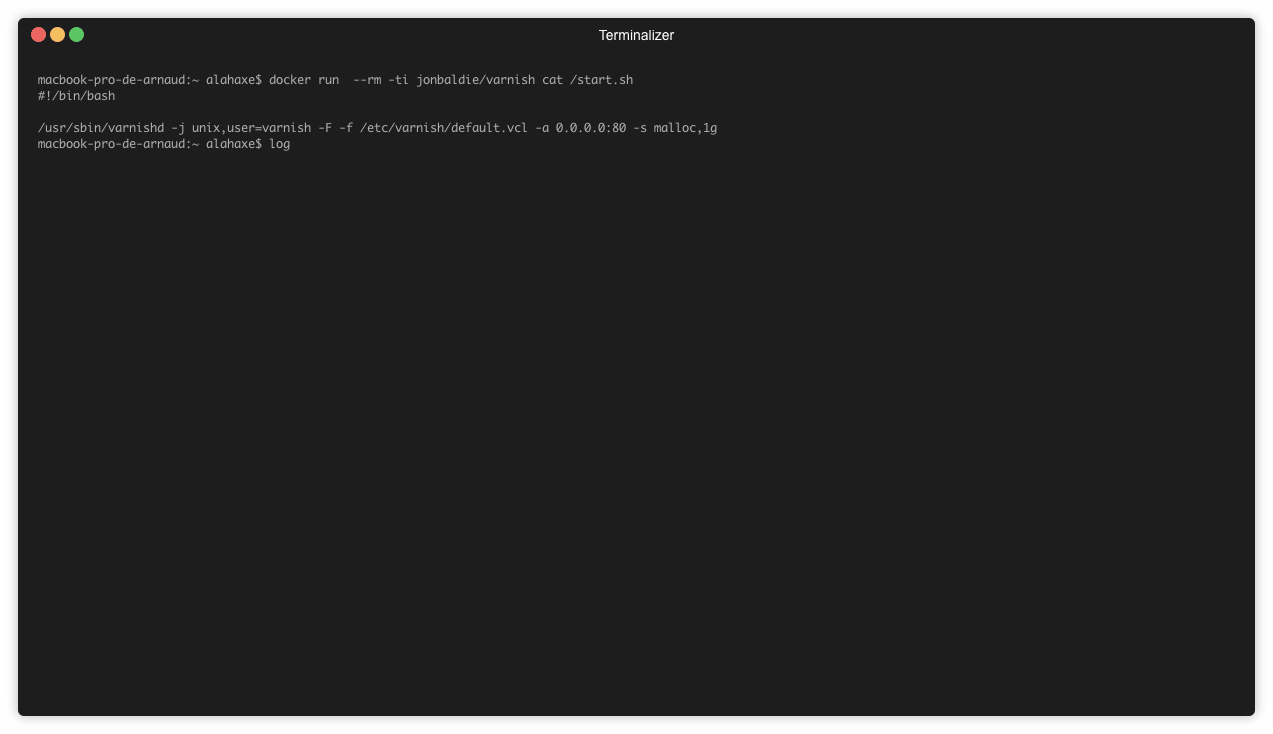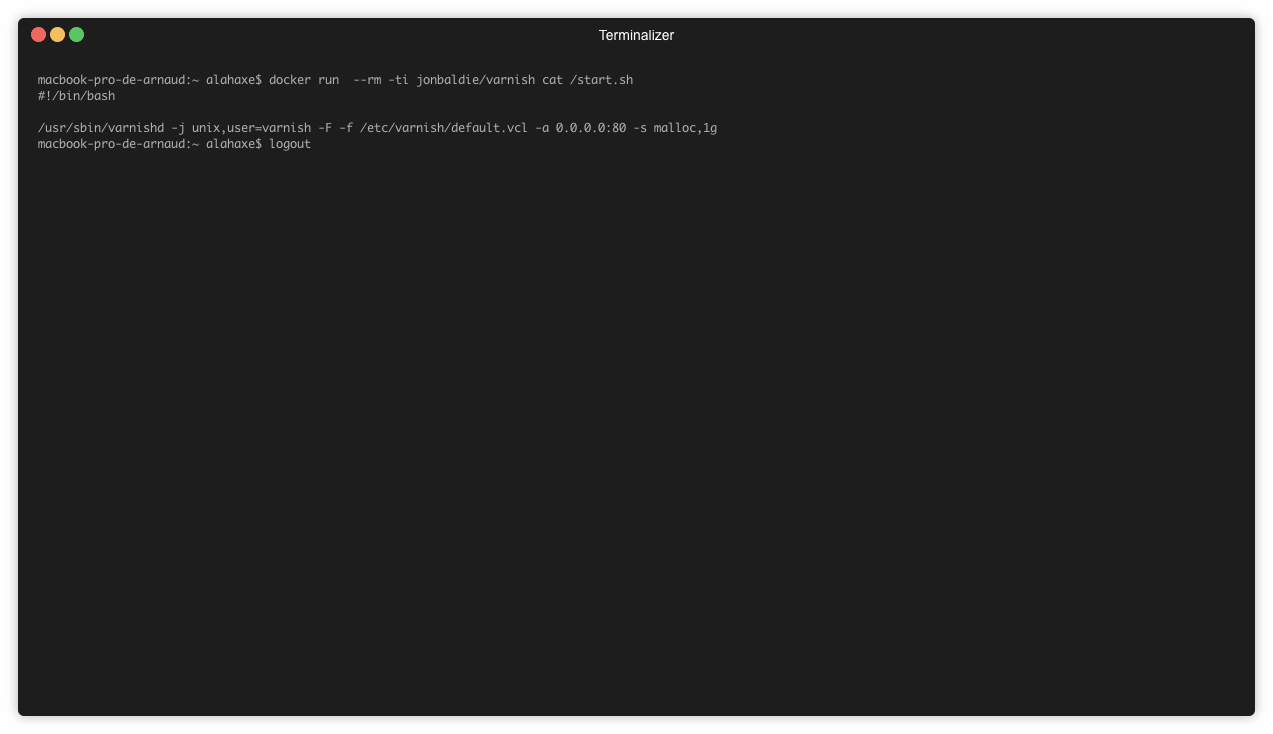
Pour un fichier toujours présent dans le dernier layer
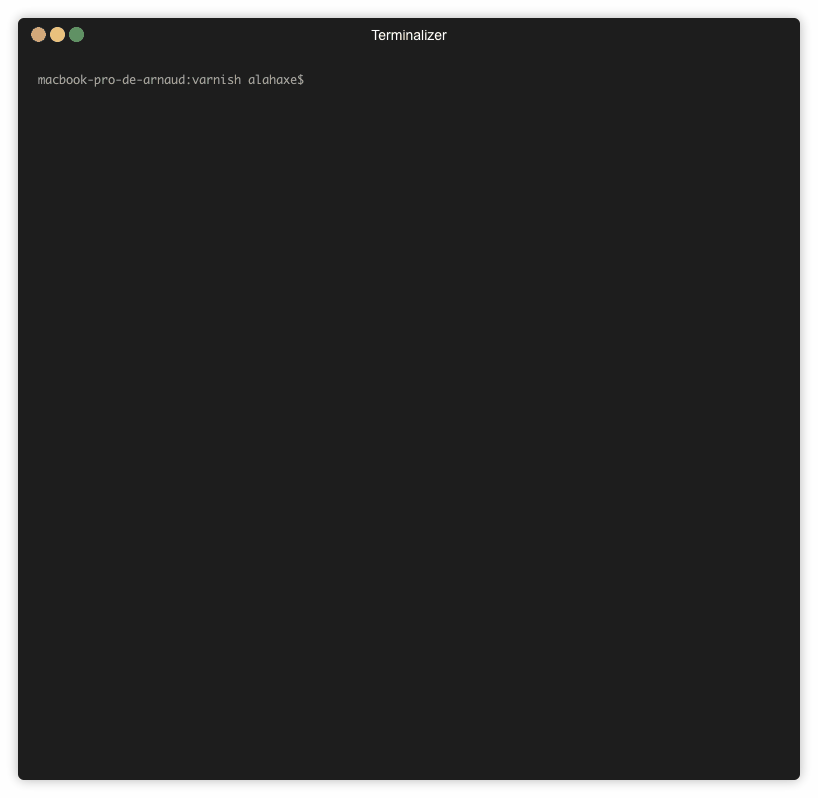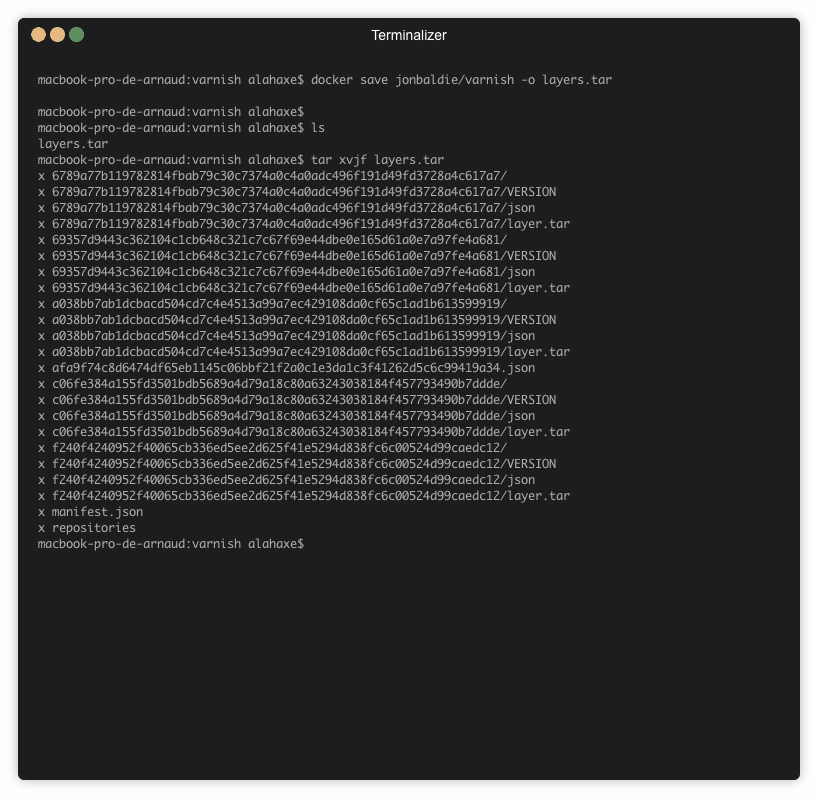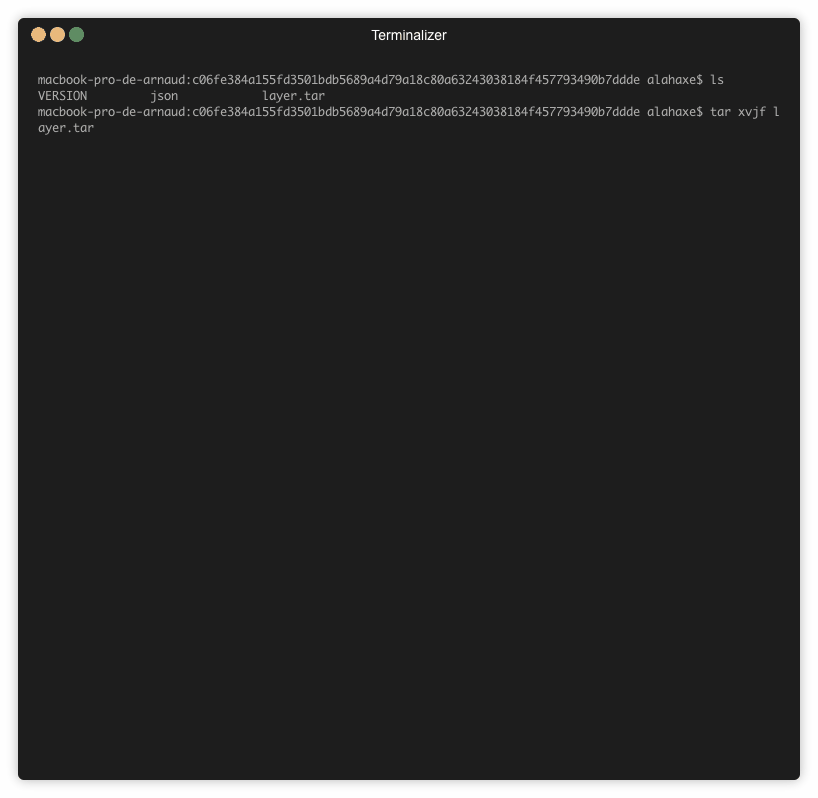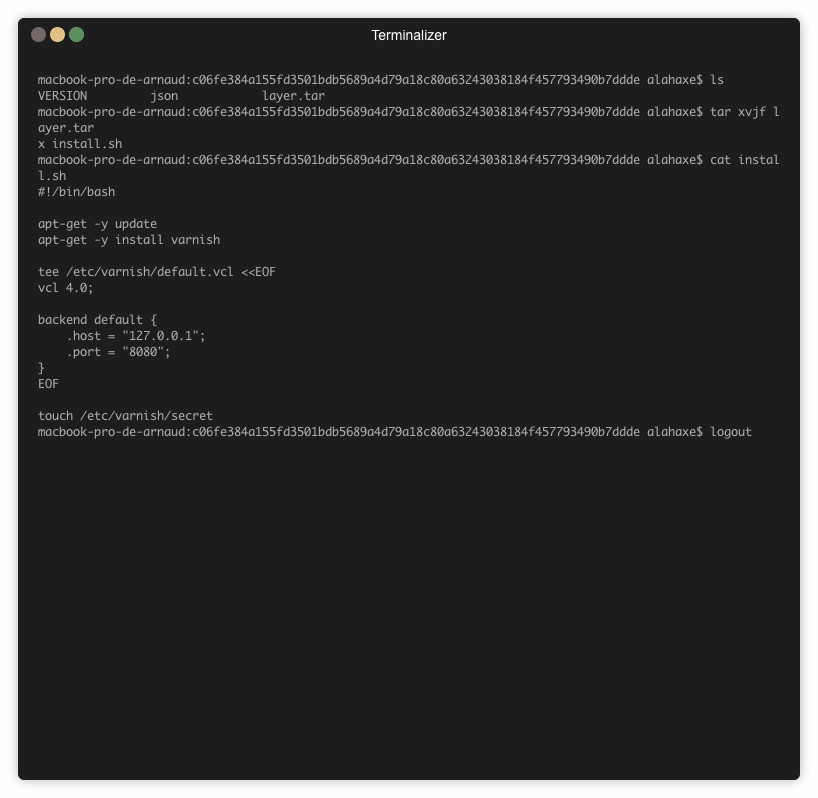
Le fichier start.sh n’est pas supprimé après l’installation. Il est donc simple de le consulter:
➜ docker run --rm -ti jonbaldie/varnish cat /start.sh
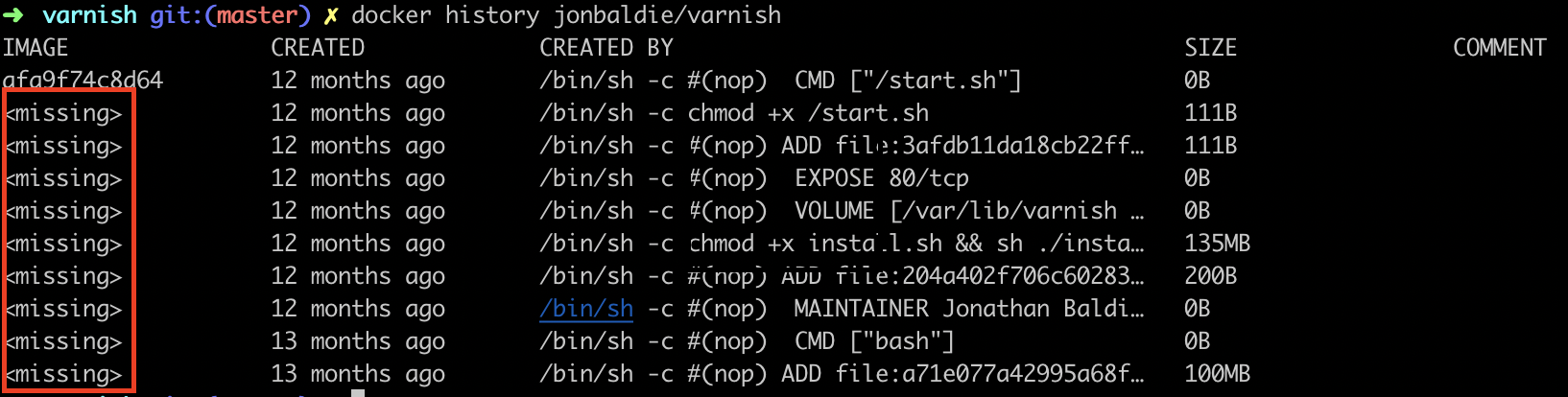
Pour un fichier non présent dans le dernier layer
Pour le fichier install.sh il ne va malheureusement pas être possible de l’afficher car il est supprimé pendant le build. Le docker history de l’image ne me donne pas d’image Id correspondant à ce layer car je n’ai pas buildé l’image sur ma machine.
Docker history sur jonbaldie/varnish
Il n’est pas possible de lancer un container sur une image qui contient le install.sh. Et c’est bien là le problème ! C’est une boîte noire.
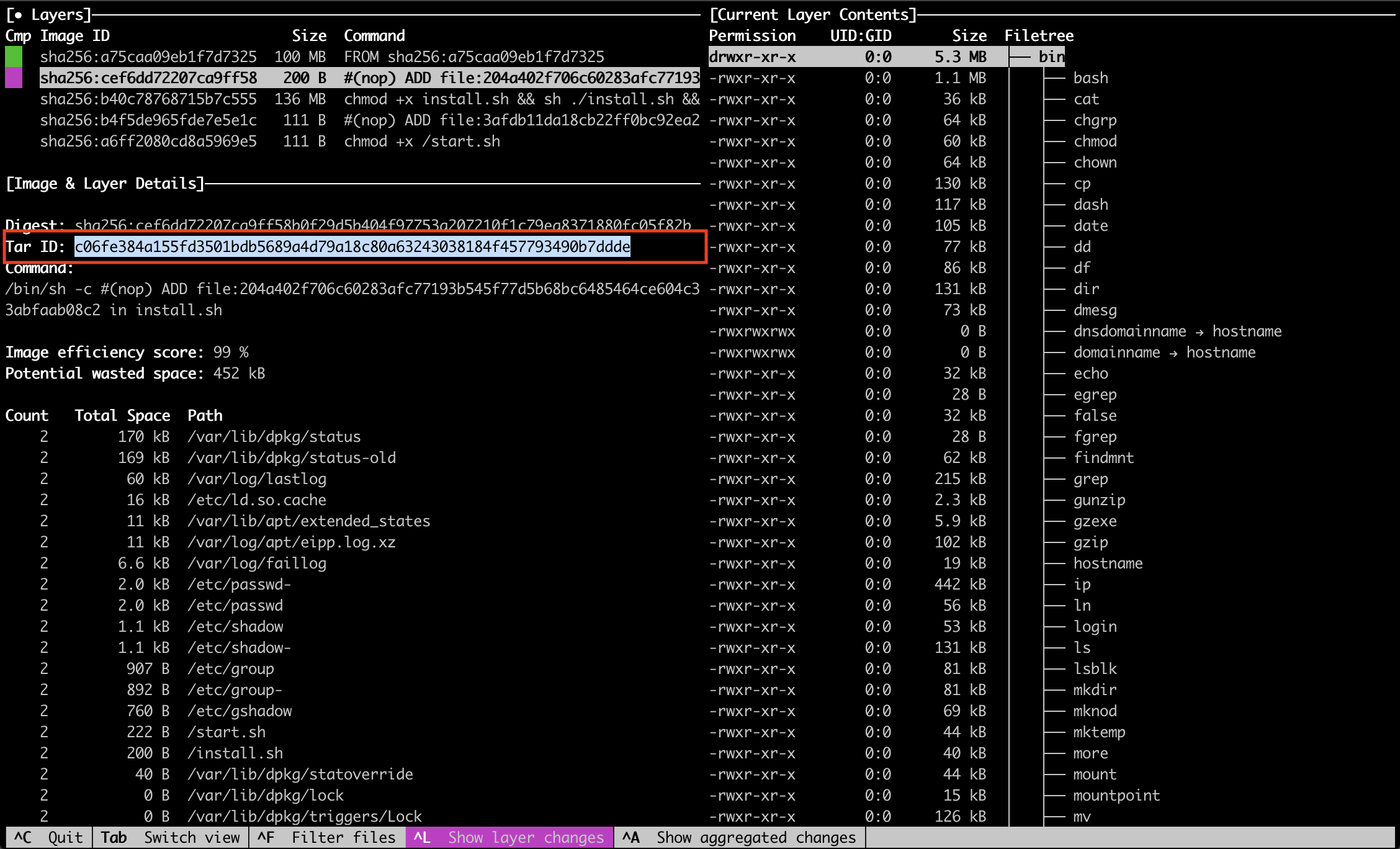
Pour arriver à consulter ce fichier il va falloir exporter l’image et naviguer dans les layers « à la main ».
Pour voir le fichier on va récupérer le tar id du layer qui nous intéresse via Dive :
On sait donc maintenant qu’il faut regarder le contenu du tar « c06fe384a155fd3501bdb5689a4d79a18c80a63243038184f457793490b7ddde » pour trouver mon fichier install.sh.
Récupérer un fichier dans un layer docker
Vérifier l’image de base
Dans notre cas l’image est construite à partir d’une debian officielle. Mais comment s’en assurer ? Est-ce que cette debian est à jour ?
Dans un premier temps on va chercher la version de debian installée :
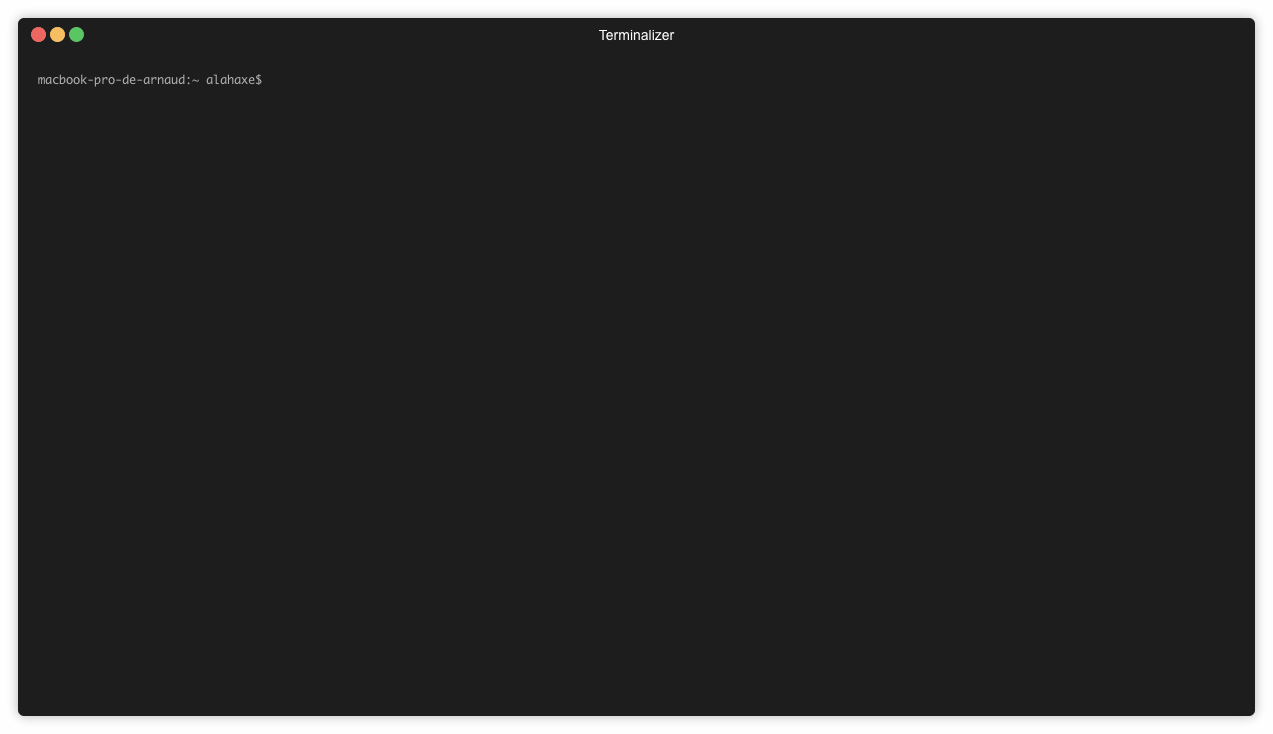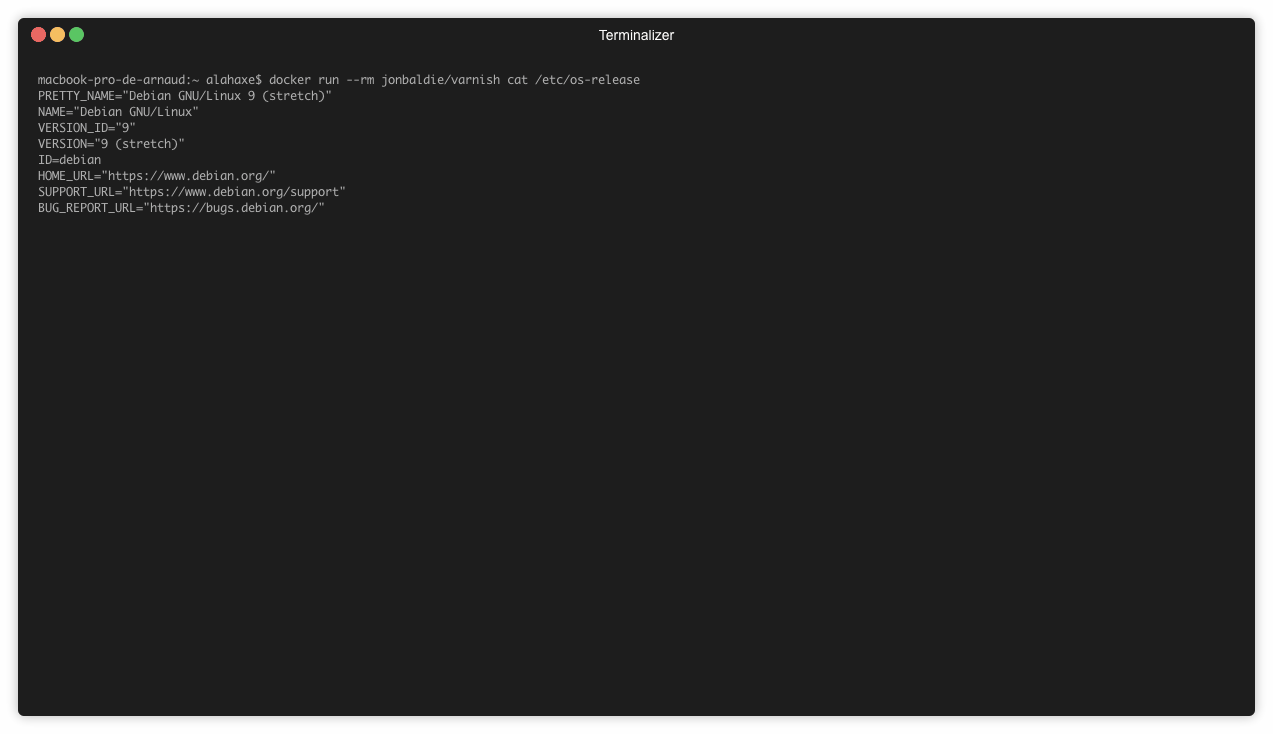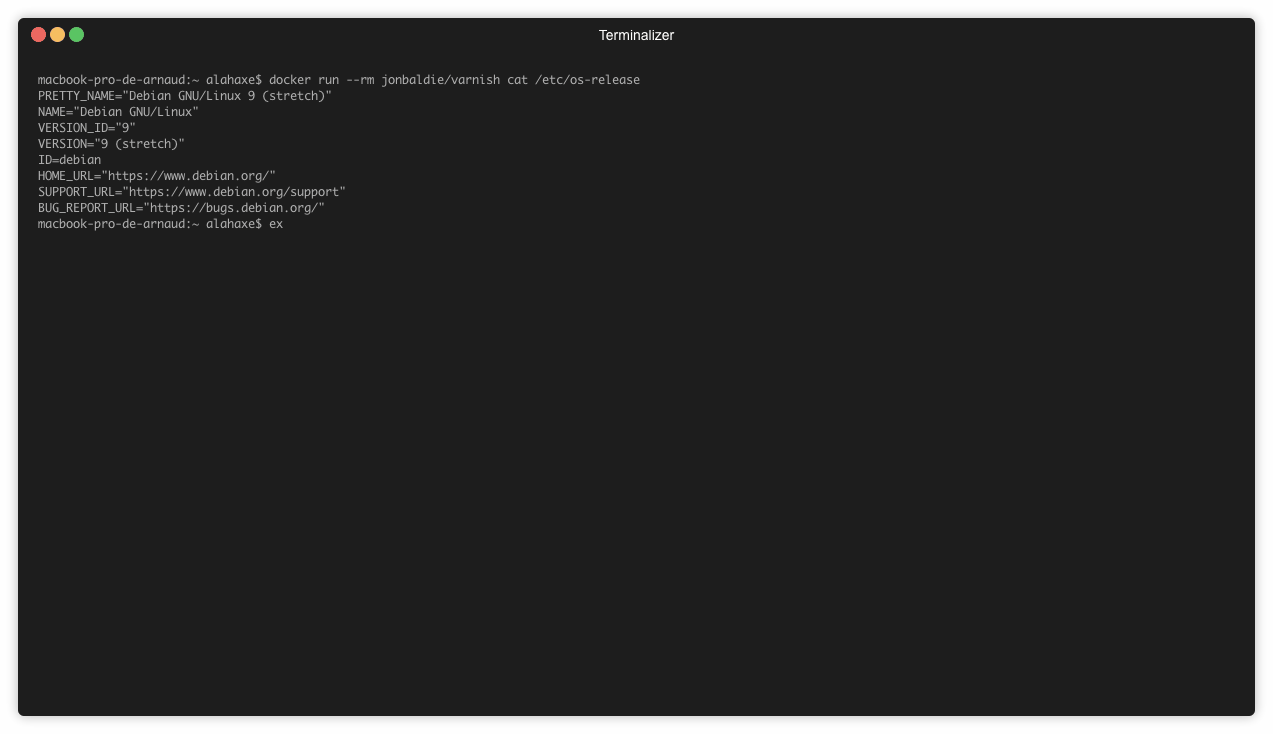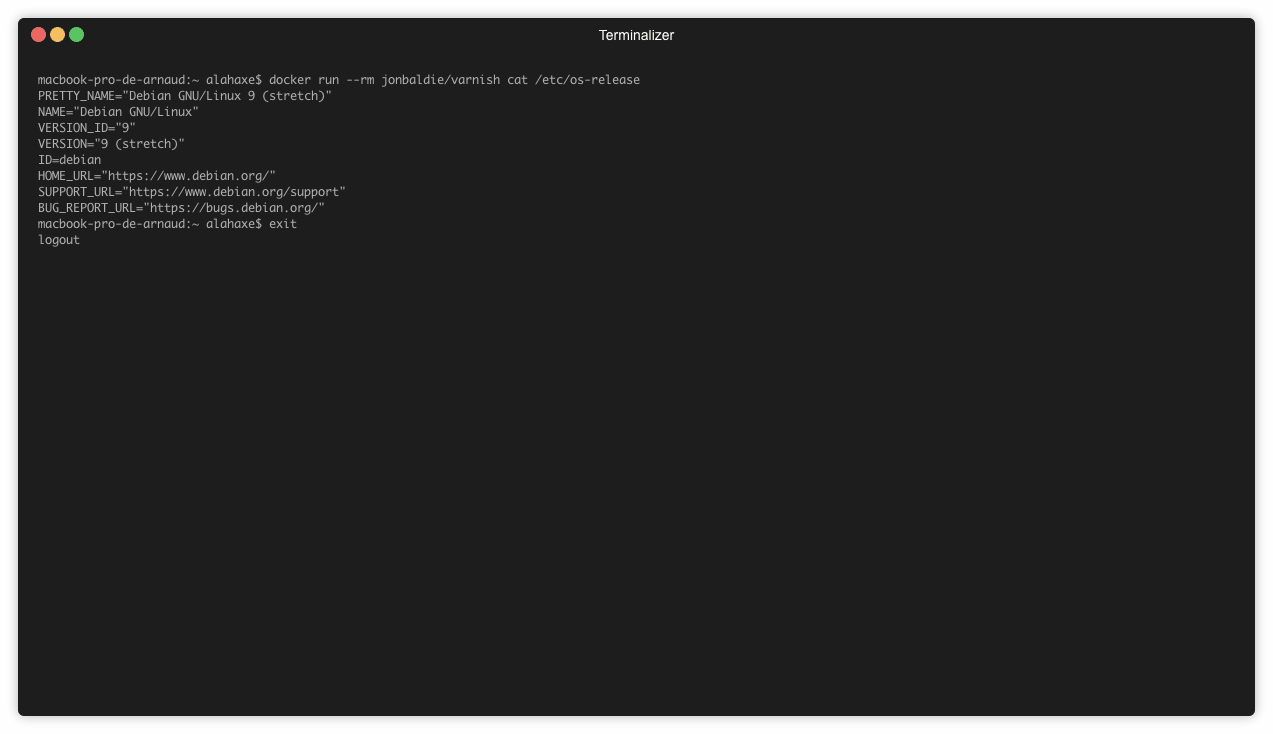
➜ varnish docker run --rm jonbaldie/varnish cat /etc/os-release
Trouver la version de debian utilisée dans une image docker
Malheureusement je ne sais pas comment vérifier que cette debian est bien une version officielle. Je ne peux pas non plus m’assurer que les mises à jour de sécurité sont faites.
Le seul indicateur de qualité à ce niveau est de regarder les builds. Cette image est buildée automatiquement sur la Docker Cloud’s infrastructure. Ce point est primordial dans le choix d’une image non officielle car cela nous donne l’assurance que le docker file affiché est bien celui qui est utilisé pour le build.
Sur le dernier build par exemple nous avons plusieurs informations à disposition :
Building in Docker Cloud's infrastructure...
Cloning into '.'...
KernelVersion: 4.4.0-93-generic
Arch: amd64
BuildTime: 2017-08-17T22:50:04.828747906+00:00
ApiVersion: 1.30
Version: 17.06.1-ce
MinAPIVersion: 1.12
GitCommit: 874a737
Os: linux
GoVersion: go1.8.3
Starting build of index.docker.io/jonbaldie/varnish:latest...
Step 1/9 : FROM debian
---> 874e27b628fd
Step 2/9 : MAINTAINER Jonathan Baldie "[email protected]"
---> Running in 3691027bb23a
---> 6e1fd6e2af21
Removing intermediate container 3691027bb23a
Step 3/9 : ADD install.sh install.sh
---> 2d9d517255c6
Removing intermediate container 1882f5bc4a22
Step 4/9 : RUN chmod +x install.sh && sh ./install.sh && rm install.sh
---> Running in 77dd464fc5be
Ign:1 http://deb.debian.org/debian stretch InRelease
//...
Get:8 http://security.debian.org stretch/updates/main amd64 Packages [227 kB]
Fetched 10.0 MB in 4s (2119 kB/s)
Reading package lists...
Reading package lists...
Building dependency tree...
Reading state information...
The following additional packages will be installed:
binutils cpp cpp-6 gcc gcc-6 libasan3 libatomic1 libbsd0 libc-dev-bin
libc6-dev libcc1-0 libcilkrts5 libedit2 libgcc-6-dev libgmp10 libgomp1
libgpm2 libisl15 libitm1 libjemalloc1 liblsan0 libmpc3 libmpfr4 libmpx2
libncurses5 libquadmath0 libtsan0 libubsan0 libvarnishapi1 linux-libc-dev
manpages manpages-dev
Suggested packages:
binutils-doc cpp-doc gcc-6-locales gcc-multilib make autoconf automake
libtool flex bison gdb gcc-doc gcc-6-multilib gcc-6-doc libgcc1-dbg
libgomp1-dbg libitm1-dbg libatomic1-dbg libasan3-dbg liblsan0-dbg
libtsan0-dbg libubsan0-dbg libcilkrts5-dbg libmpx2-dbg libquadmath0-dbg
glibc-doc gpm man-browser varnish-doc
The following NEW packages will be installed:
binutils cpp cpp-6 gcc gcc-6 libasan3 libatomic1 libbsd0 libc-dev-bin
libc6-dev libcc1-0 libcilkrts5 libedit2 libgcc-6-dev libgmp10 libgomp1
libgpm2 libisl15 libitm1 libjemalloc1 liblsan0 libmpc3 libmpfr4 libmpx2
libncurses5 libquadmath0 libtsan0 libubsan0 libvarnishapi1 linux-libc-dev
manpages manpages-dev varnish
0 upgraded, 33 newly installed, 0 to remove and 1 not upgraded.
Need to get 30.5 MB of archives.
After this operation, 123 MB of additional disk space will be used.
Get:1 http://deb.debian.org/debian stretch/main amd64 libbsd0 amd64 0.8.3-1 [83.0 kB]
//...
Get:33 http://deb.debian.org/debian stretch/main amd64 varnish amd64 5.0.0-7+deb9u1 [690 kB]
[91mdebconf: delaying package configuration, since apt-utils is not installed
[0m
Fetched 30.5 MB in 1s (18.9 MB/s)
Selecting previously unselected package libbsd0:amd64.
Preparing to unpack .../00-libbsd0_0.8.3-1_amd64.deb ...
//...
Setting up varnish (5.0.0-7+deb9u1) ...
Processing triggers for libc-bin (2.24-11+deb9u1) ...
vcl 4.0;
backend default {
.host = "127.0.0.1";
.port = "8080";
}
---> 0953378c3b8d
Removing intermediate container 77dd464fc5be
Step 5/9 : VOLUME /var/lib/varnish /etc/varnish
---> Running in c56c31df17fb
---> e7f1ae57b0f0
Removing intermediate container c56c31df17fb
Step 6/9 : EXPOSE 80
---> Running in e1f015e6366e
---> 6000a2d9d149
Removing intermediate container e1f015e6366e
Step 7/9 : ADD start.sh /start.sh
---> 085cec1148a7
Removing intermediate container 73e8ab753261
Step 8/9 : RUN chmod +x /start.sh
---> Running in 8ab33da3607a
---> 06f67d6546ac
Removing intermediate container 8ab33da3607a
Step 9/9 : CMD /start.sh
---> Running in 3910129787df
---> afa9f74c8d64
Removing intermediate container 3910129787df
Successfully built afa9f74c8d64
Successfully tagged jonbaldie/varnish:latest
Pushing index.docker.io/jonbaldie/varnish:latest...
Done!
Build finished
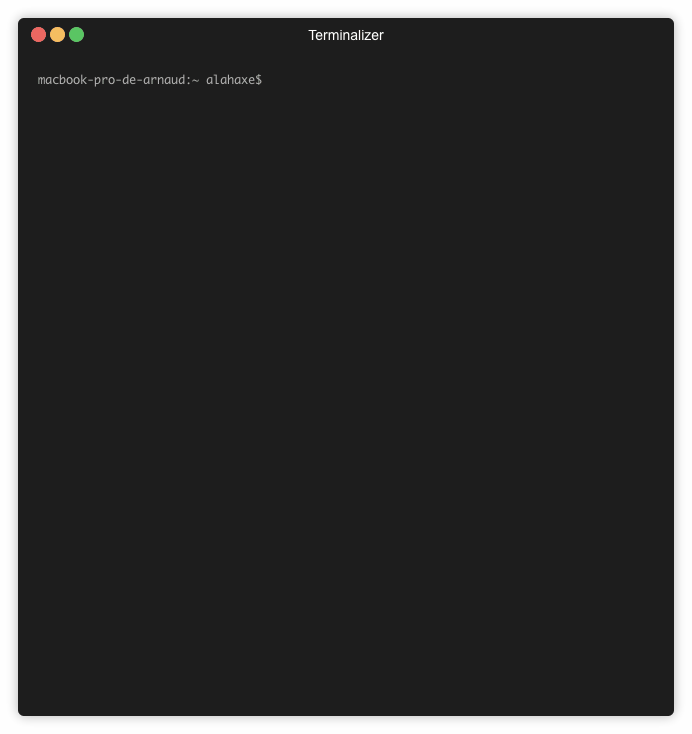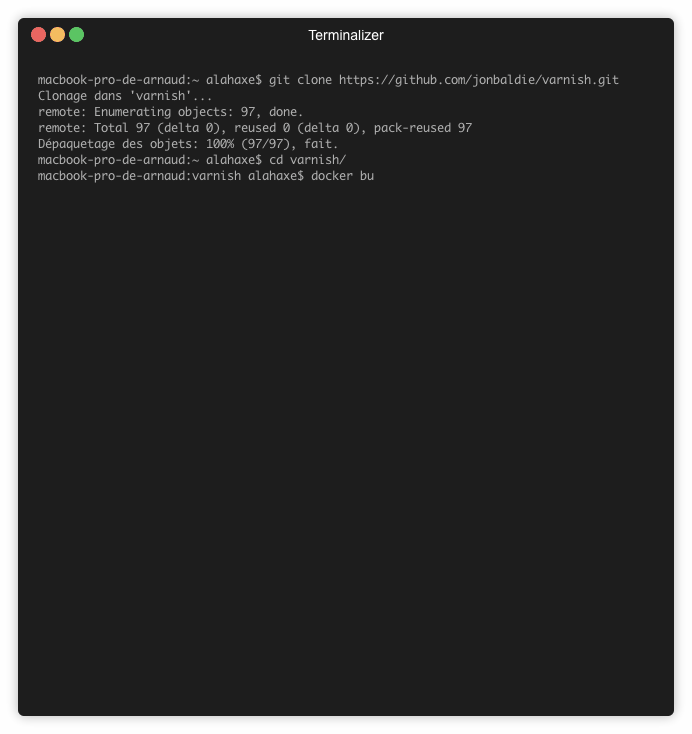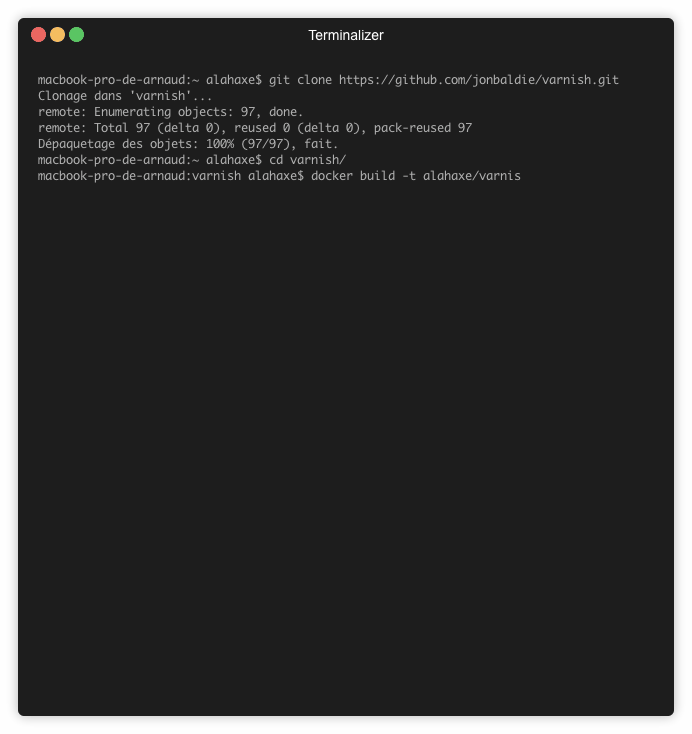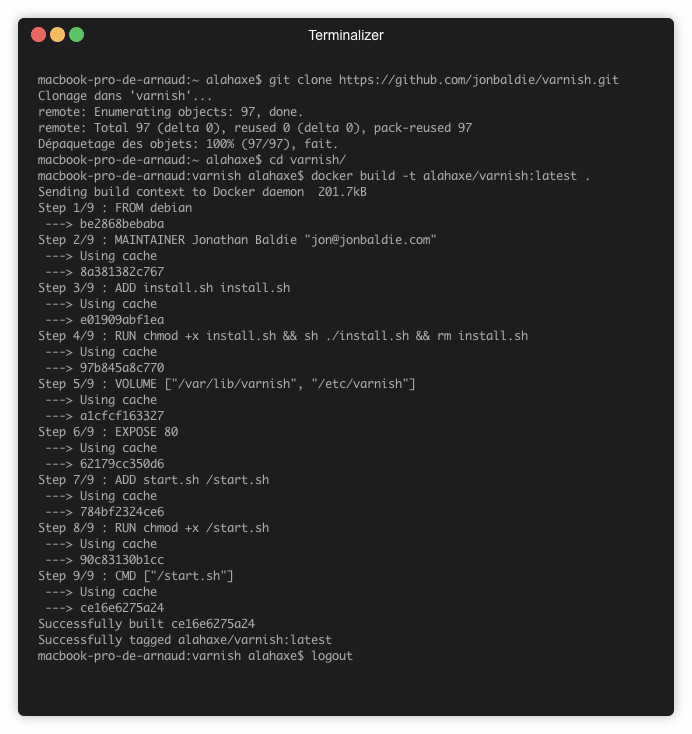
Première information, l’image est bien construite à partir de l’image debian officielle comme on peut le voir à la step 1: « Step 1/9 : FROM debian ».
Seconde information, l’image a été buildée le 17 Août 2017. Toutes les failles détectées depuis cette date sur varnish et debian stretch ne sont donc pas patchées.
Pour les images qui ne sont pas buildées automatiquement sur la plateforme je ne sais pas si c’est possible de vérifier l’intégrité de l’image de base. J’ai tenté plusieurs approches mais comme l’image utilise une « latest » et qu’elle a été remplacée par une nouvelle version je ne vois pas comment faire pour retrouver mon layer. Si vous avez une solution, je suis preneur.
Builder ses propres images
La solution qui présente le moins de risques est de builder soi-même ses images à partir des Dockerfiles mis à disposition par les contributeurs. De cette manière on peut faire une revue complète du code et des dépendances. En buildant moi-même mon image je pourrais avoir une version plus à jour de debian et de varnish.
Builder une image docker depuis les sources github
Conclusion
Il faut absolument se méfier des images mises à disposition sur le Dockerhub. Avant d’utiliser une image on doit se poser au minimum les questions suivantes :
Est-ce que l’image est officielle ou buildée automatiquement ?
Si non, est-ce que les sources sont disponibles ?
Si oui, est-ce que le dockerfile présenté est vraiment celui qui a servi à builder l’image ?
De quand date la dernière build ?
Au moindre doute il est préférable de builder sa propre version de l’image ou d’en utiliser une autre.
A la vue de cet article, on me dira surement que la stack technique du site Cocktailand est overkill.
Ma réponse est simple: « Ouaip carrément !«
Au-delà du plaisir de travailler sur la thématique des cocktails, je travaille sur ce projet aussi pour me faire plaisir techniquement et pour tester des technologies ou des services en mode SAS.
Comme j’ai toujours la flemme de documenter mes sides projects, cet article fera office de documentation « technique ».
Je vais donc découper cet article en trois parties:
L’hébergement
L’application
Les services SAS utilisés
L’hébergement
Scaleway
Depuis la beta de scaleway, filiale de Online, je prends tous mes serveurs persos chez eux. Ils sont à la fois fiables, efficaces et abordables. Il n’y a pas de frais d’installation et on peut libérer un serveur à tout moment. Pour Cocktailand, j’ai pris deux serveurs pour démarrer, un pour la prod et un pour les backups qui n’a pas d’accès à Internet (ni entrant ni sortant). Pour toute la partie métrique graphite/ grafana, j’ai pluggué le site sur mon infra existante.
Le serveur qui héberge le site est un START1-S. Ce n’est pas une bête de course, mais au besoin je passerai à la gamme au-dessus.
Cloudflare
Cloudflare est un gestionnaire de DNS en ligne qui a pour particularité d’avoir un temps de propagation proche de 0. Dans son offre de base, qui est gratuite, il permet de gérer plusieurs noms de domaine, il autorise les wildcards dans les sous-domaines, mais il propose aussi tout un tas d’autres fonctionnalités intéressantes. En effet, dans l’offre gratuite, il propose:
Une protection DDOS
Une optimisation des assets à la volée
Une redirection http vers https automatique
Une modification des urls des assets des pages de http vers https (un garde-fou sympa si on est full https)
Une redirection automatique vers un site mobile (s’il est différent)
La possibilité de bannir des ips (manuellement ou via une API)
…
Pour ma part, je l’utilise depuis longtemps et je n’ai jamais eu à me plaindre du moindre dysfonctionnement.
Docker compose
La stack du site est entièrement gérée avec docker.
Chaque brique de la partie docker (varnish, nginx, phpfpm ) peut scaller horizontalement.
Pour le moment, le serveur MySQL ainsi que les images ne sont pas scallables. Je travaillerai sur les deux points si jamais le besoin s’en fait sentir. Normalement, avec l’utilisation intensive de varnish qui est faite, la base de données n’est pas énormément sollicitée.
L’application
Le site est développé avec le framework Symfony. J’ai choisi SF pour sa stabilité, sa fiabilité, mais aussi car j’ai l’habitude de travailler avec au quotidien. Je sais que, bien utilisé, il est capable de tenir la charge.
Le site fait un usage assez intensif des ESI afin de permettre une gestion du cache http assez fine. Quasiment chaque bloc de la home est un ESI. Il est par exemple possible d’avoir un temps de cache de quelques heures pour le cocktail du jour et un cache d’une journée sur le top des cocktails les plus consultés.
Images
La problématique n’est pas de trouver des recettes de cocktails, mais de trouver des images libres de droits. Je n’ai malheureusement pas eu le temps de confectionner par moi-même l’ensemble des cocktails présents sur le site.
Voici donc une liste non exhaustive des sites sur lesquels je vais chercher des images quand je n’en ai pas:
Comme je l’ai dit plus tôt, Cocktailand a aussi pour but de tester des technologies ou des services en SAS.
Algolia
Surnommé le « Google des apps », Algolia est un service externe de moteur de recherche. Il remplace le bon vieux cluster ElasticSearch que j’aurais pu mettre sur mon serveur.
En plus d’être extrêmement performant, algolia a un service client au top.
L’offre gratuite me permet largement de faire tourner mon moteur de recherche sans restriction et avec des temps de réponse aux alentours de 50ms. La seule contrepartie demandée par algolia est de préciser que la recherche est fournie par eux en dessous des résultats.
Très franchement, je suis agréablement surpris par cette techno.
Logz.io
Logz est un agrégateur de logs en mode SAS. Comme je n’ai rien de critique dans les logs, je me suis permis de les externaliser. On retrouve une bonne vieille stack ELK.
Pour envoyer les logs, il m’a suffi d’ajouter leur container docker rsyslog dans ma stack docker-compose. Une fois les bonnes variables d’environnements mises en place les logs remontent chez eux en quasi temps réel.
Au-delà de la simple consultation et recherche dans les logs, ils proposent un outil d’alerting. Il est par exemple possible d’envoyer un mail quand un grand nombre d’exceptions ou de fatales sont remontées.
Coût de la plateforme
Comme le site est encore récent et qu’il ne génère aucun revenu, j’ai fait le maximum pour réduire les coûts.
Voici un état des lieux des dépenses engendrées par Cocktailand.