Pi-hole est un projet open-source prévu pour tourner sur un raspberry pi, qui permet de filtrer les requêtes DNS dans le but de bloquer les publicités et le tracking. L’idée est de faire ce filtrage au niveau du réseau afin de pouvoir bloquer aussi les publicités dans les applications et sur les navigateurs mobiles qui n’ont pas forcement d’Adblock.
Pour mon installation j’ai ressorti un vieux raspberry 1 b+ et j’ai utilisé l’installation recommandé sur le site:
curl -sSL https://install.pi-hole.net | bash
Avant de lancer la commande, pensez-bien à vérifier le script.
Par la suite j’ai laisser tout les paramètres à leurs valeurs par défaut.
Sur ma box j’ai fixé une IP fixe pour le raspberry (192.168.1.254).
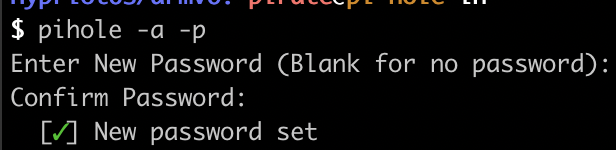
Une fois l’installation terminé l’interface web est accessible à l’URL http://192.168.1.254/admin. A la fin de l’installation un mot de passe vous a été donné. Mais si vous l’avez perdu vous pouvez le réinitialiser via la commande:
pihole -a -p
Maintenant il ne reste plus qu’à utiliser notre nouveau serveur DNS en tant que DNS primaire.
Si comme moi vous avez une livebox, vous allez être heureux d’apprendre que vous ne pouvez pas/plus changer les DNSs au niveau de la box. J’ai donc coupé le wifi de la livebox et ajouté un routeur wifi qui lui va me servir de DHCP et qui va s’occuper de résoudre les requêtes DNS en passant par pi-hole.
Si vous ne souhaitez pas ajouter un routeur WIFI, et que ne vous ne pouvez pas modifier les DNS de votre box, il faudra modifier manuellement les DNS sur chaque PC, téléphone et tablette. (c’est vraiment pas idéal)
Après quelques heures d’utilisation j’ai constaté que 15% des resolutions DNS qui sont fait dans le cadre d’une navigation classique sont vers des sites de tracking ou de publicité. Je suis franchement surpris car je m’attendais à bien pire…
Il possible d’ajouter manuellement ou via un fichier accessible en HTTP des domaines à bloquer/autoriser.
En quelques minutes d’installation, grace à pi-hole, il est possible de limiter le tracking est la publicité pour l’intégralité de votre réseau local. Simple mais efficace.
Si on veux aller un peux plus loin dans le blocage ont peux ajouter des listes de noms de domaines maintenues par la communauté. Avec cette liste vous passerez à plus de 600 000 domaines de bloqués.
Pour les ajouter il faut se rendre dans Settings > Blocklists et il faut simplement coller la liste des listes de domaines tel quel dans le champs text et enregistrer.
Petit test de navigation sur mon téléphone avec et sans pi-hole:
Mole est une application en ligne de commande qui permet de simplifier la création de tunnels SSH.
Il est parfois utile de monter un tunnel pour accéder à un service qui n’est pas ouvert sur le WEB. Par exemple si votre serveur MYSQL, n’est accessible que depuis votre serveur web ou votre serveur de backup. Ou encore pour contourner un firewall qui bloquerait un port en particulier.
Sur cet exemple le serveur bleu ne peut pas accéder au port 80 (application web) du serveur rouge car un firewall le bloque. Mais le port 22 (ssh) est accessible. Il est donc possible de créer un tunnel qui forward le port 80 sur serveur rouge sur le port 8080 du serveur bleu. Une fois le tunnel mis en place il sera possible d’accéder à l’application web du serveur rouge via l’url: http://blue:8080.
Installation
Deux méthodes d’installation sont possibles. Via le script d’installation ou via homebrew pour les utilisateurs de mac.
Pour se connecter à un serveur mysql qui n’est pas ouvert sur le web nous allons ouvrir un tunnel entre le port 3306 local du serveur et le port 3307 de mon mac :
Je peux maintenant me connecter au serveur mysql du serveur sur le port 3307 de ma machine :
➜ mysql connect -h 127.0.0.1 -P 3307 -uxxxxxxx -p
Gestion des alias
Le dernier point qui est bien pratique si vous avez à jongler avec plusieurs serveurs c’est la gestion des alias. Il est possible d’enregister des alias pour les tunnels que l’on a fréquemment à créer.
Phpstan est un outil en ligne de commande qui va vous permettre de détecter automatiquement les erreurs les plus simples en scannant l’intégralité de votre projet.
Démonstration phpstan
De base, l’outil va analyser une application PHP sans tenir compte des spécificités des différents frameworks et librairies. C’est pourquoi il existe des extensions comme PHPstan Symfony pour affiner l’analyse.
Si comme moi vous voulez l’utiliser sur un projet qui a beaucoup de legacy (plus de 10 ans) vous allez avoir un rapport gigantesque. Il faut trouver des solutions pour réduire le rapport à la pull request (merge request) que l’on doit relire.
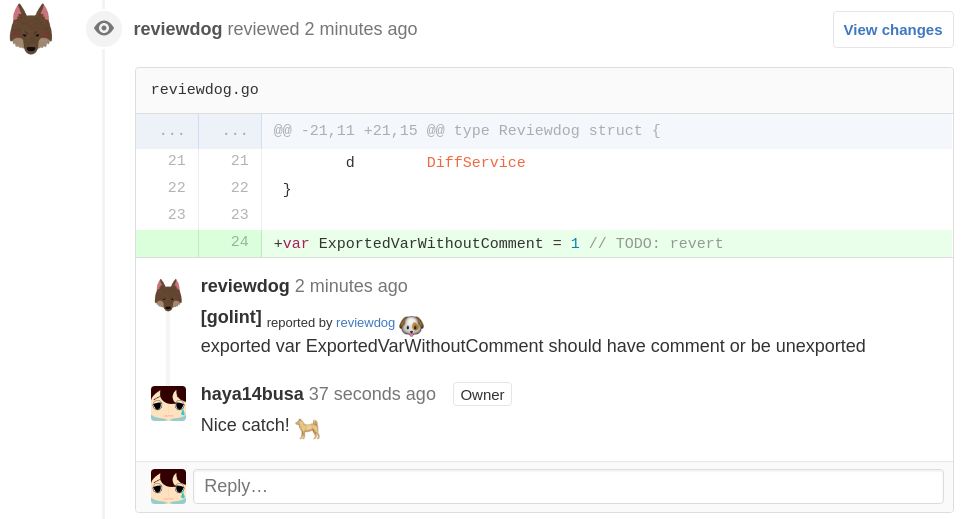
Il existe justement un outil qui permet de faire cette corrélation entre le diff et le rapport de PHPstan. Reviewdog est une application en go qui permet de prendre en entrée le rapport d’un outil d’analyse de code comme eslint, golint ou dans notre cas PHPstan.
Il se reste que deux anomalies, et elles sont directement liées au diff entre la branche courante et master.
Reviewdog peut se connecter directement sur votre gitlab ou github pour ajouter des commentaires dans les pull requests.
Tout ceci ne remplace pas une relecture par un « humain » mais cela va nous donner des indicateurs de qualité et va vous délester des vérifications les plus simples (Est-ce que cette méthode/ classe existe ?). Selon le niveau de vérification que l’on donne à PHPstan on va pouvoir vérifier plus ou moins de choses, comme les dockblocks par exemple.
Ce qui est assez intéressant c’est que PHPstan est extensible et qu’il est donc possible de créer nos propres vérifications. Il serait donc possible, par exemple, de remonter une alerte quand on utilise une classe ou méthode marquée comme dépréciée dans notre code.
Au travail nous avons pour politique de builder et de maintenir nos propres images docker. Mais pour un projet perso j’utilise des images docker publiques. Je m’efforce d’utiliser au maximum des images officielles mais certaines contributions de la communauté sont parfaites pour mes besoins. Le problème est de savoir avec certitude ce que contient un image. Une image téléchargée sur un hub est une boîte noire qu’il faut inspecter avant de l’utiliser.
Cas d’images corrompues
Il y a l’exemple de l’utilisateur docker123321 qui a diffusé 17 images contenant des backdoors sur dockerhub. Parmi les images il y a tomcat, mysql ou encore cron. Avec quasiment 5 millions de téléchargements docker123321 a réussi à miner plus de 500 Moneros en plus des portes d’entrées qu’il a créées sur le serveur.
Contenu d’une image docker
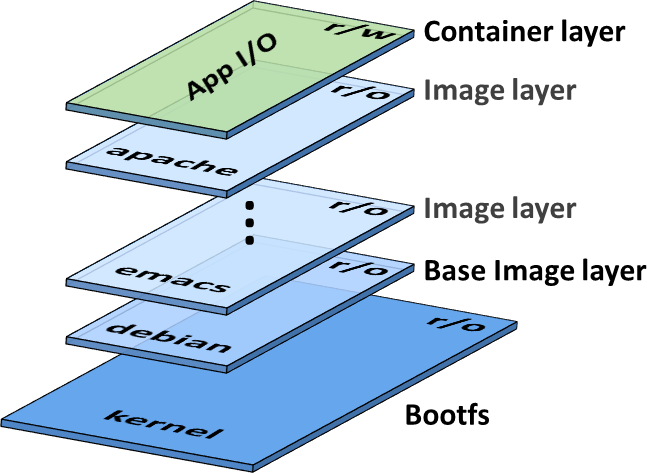
Une image docker est une succession de couches (layers) qui contiennent une liste de modifications du système de fichiers. On peut faire une analogie avec GIT où chaque layer serait un commit. Au moment de la création d’un container un layer est ajouté au-dessus de ceux de l’image. Mis à part ce layer « applicatif » les layers sont en read only.
Dive est un programme écrit en Go qui va vous permettre d’en savoir plus sur une image avant de l’utiliser. Il ne va pas permettre de s’assurer à 100% que l’image n’est pas corrompue mais il va pouvoir nous donner des information précieuses.
Pour l’installation je vous laisse vous référer au readme du projet.
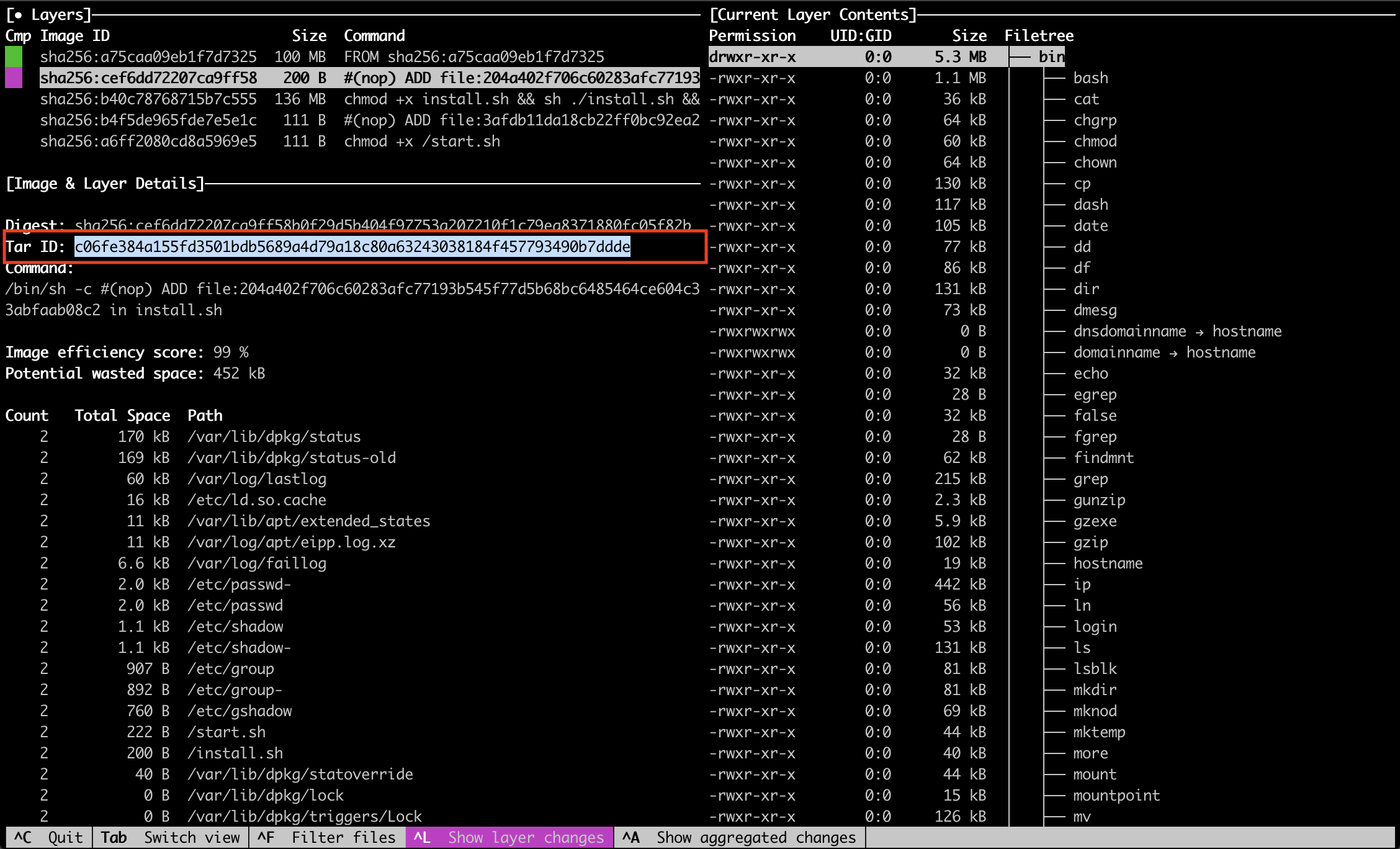
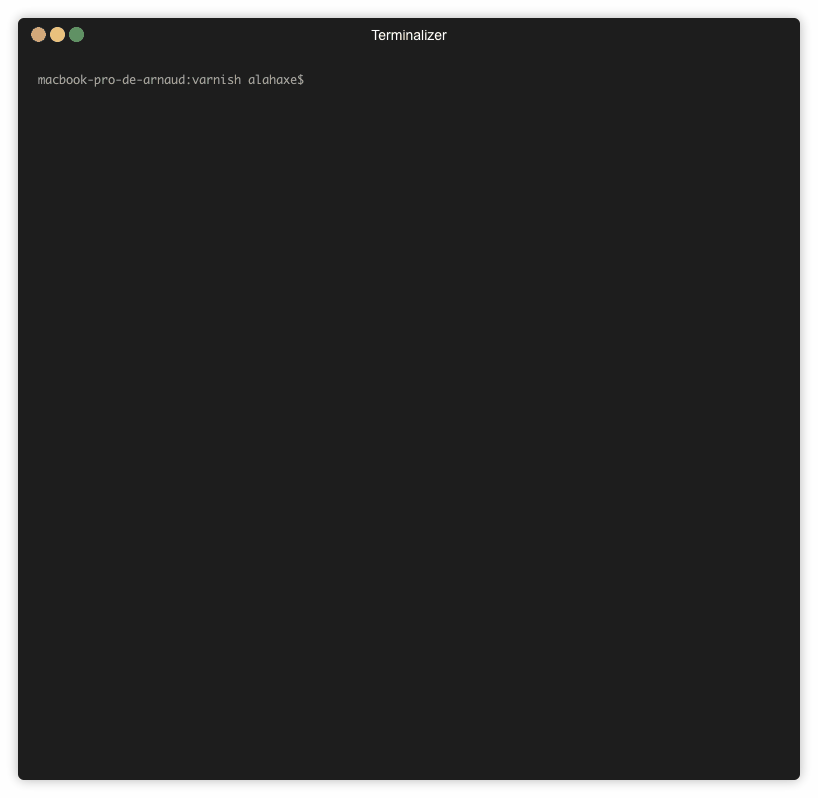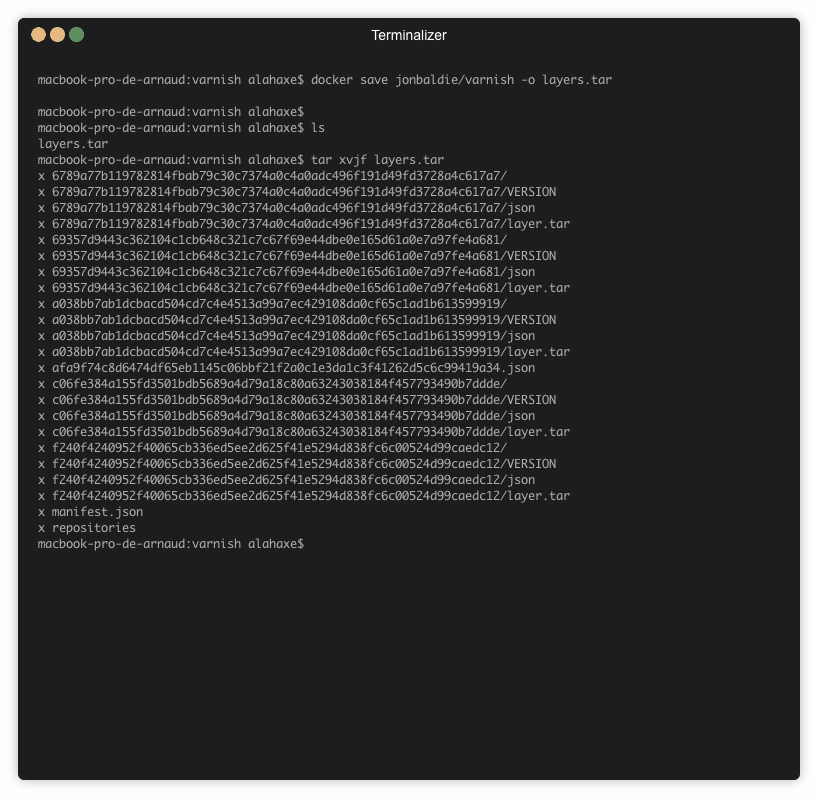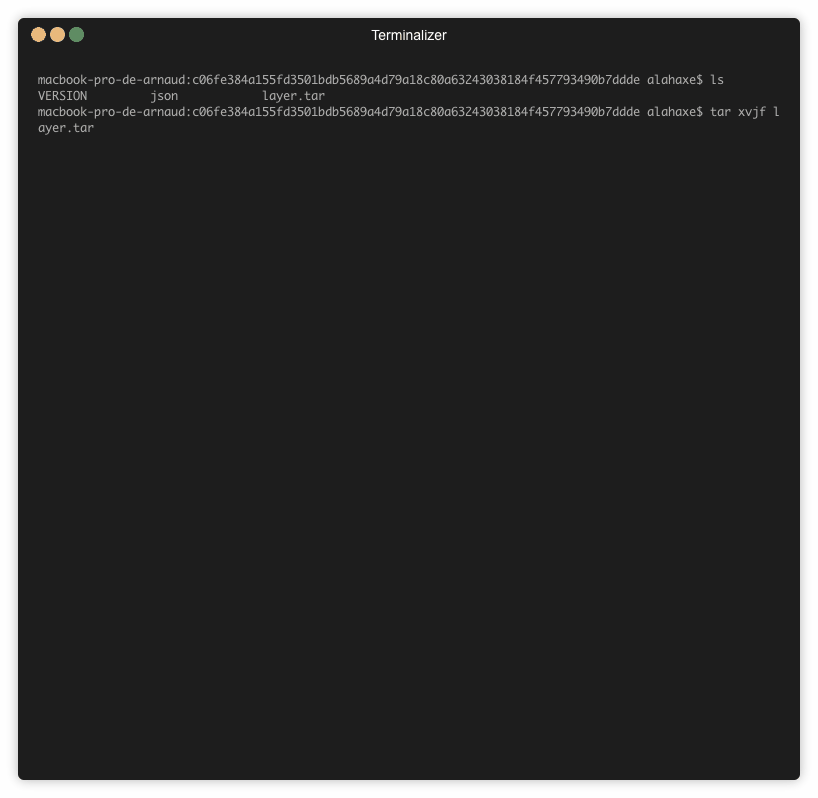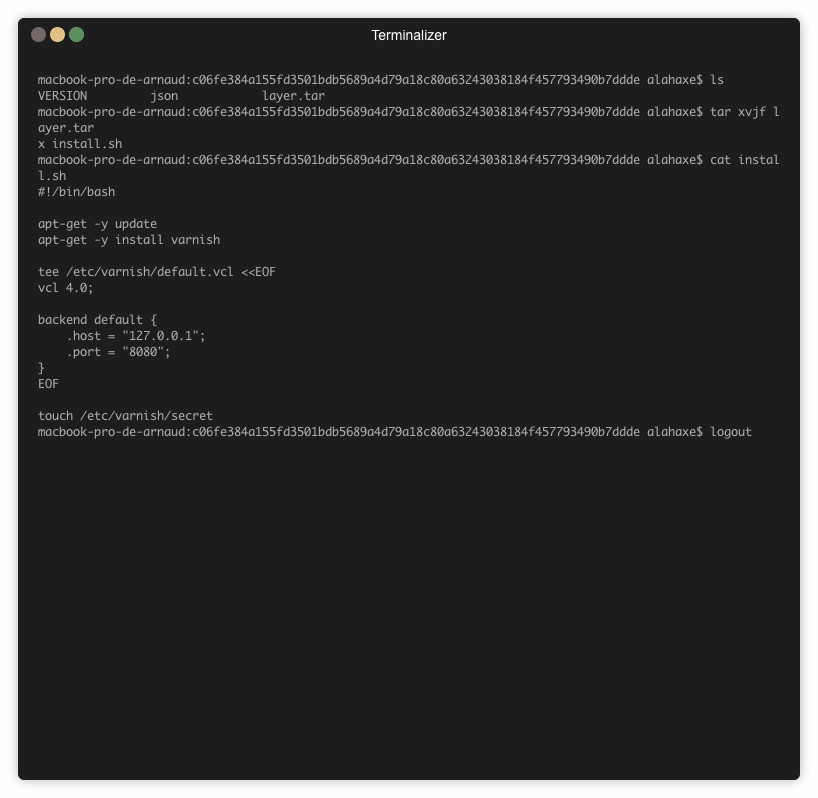
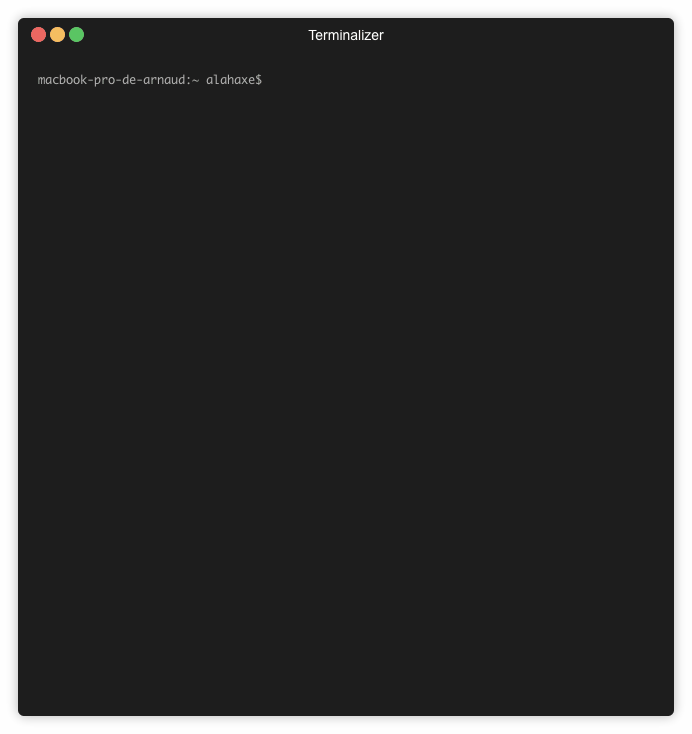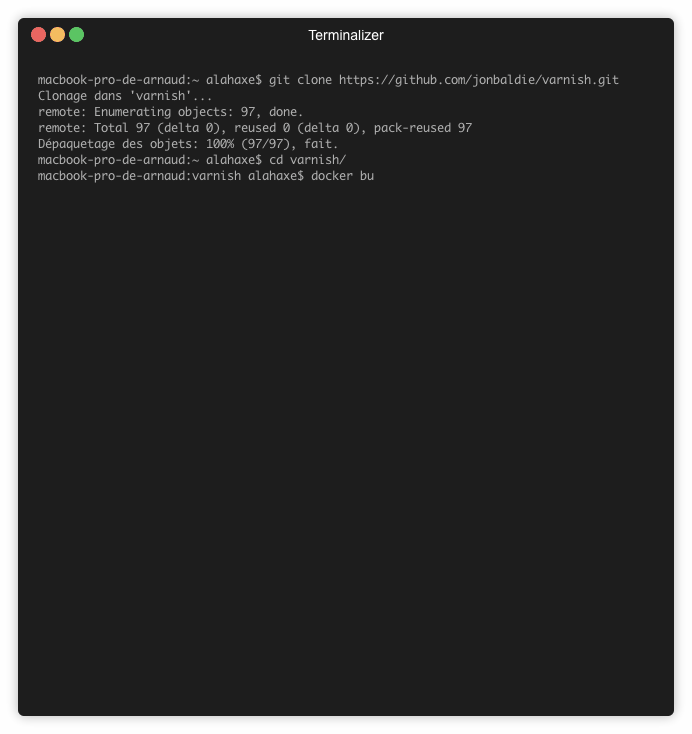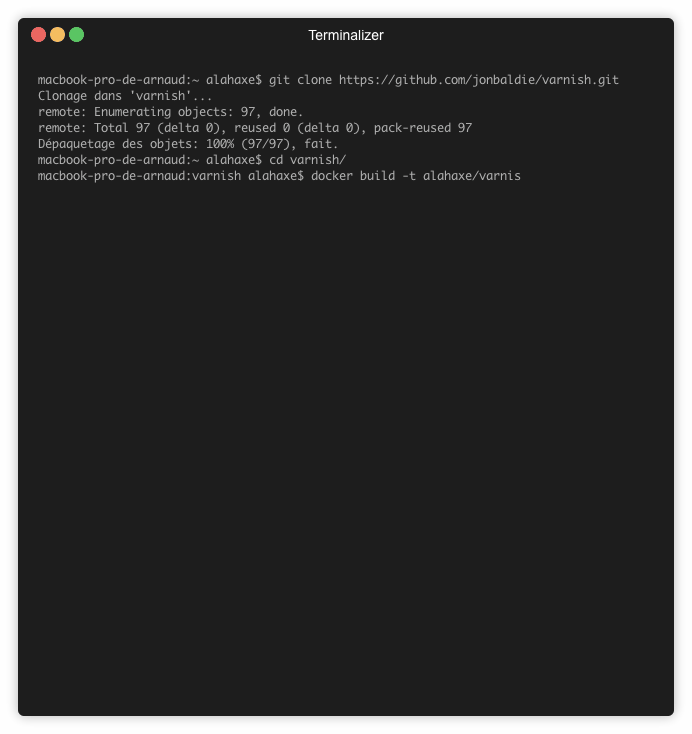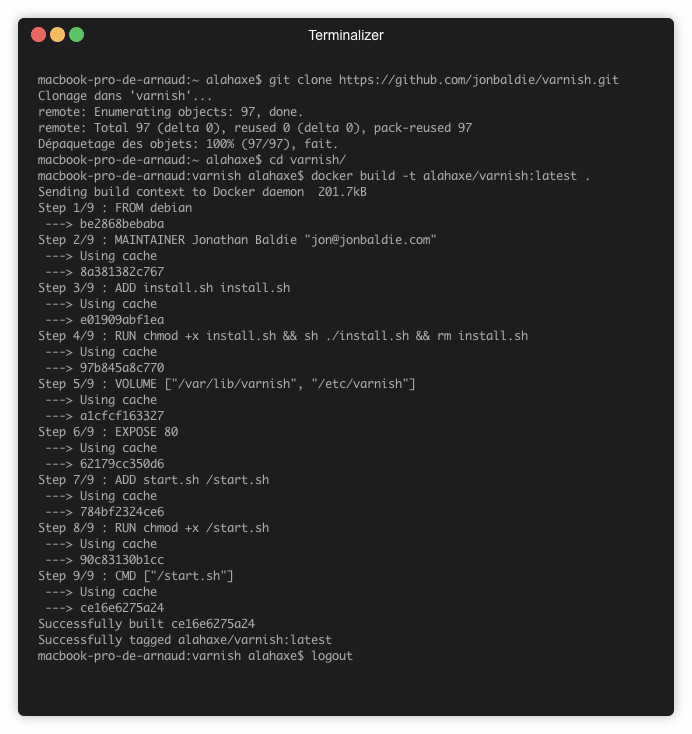
Voici un exemple d’utilisation sur l’image jonbaldie/varnish que j’utilise pour un projet perso.
➜ dive jonbaldie/varnish
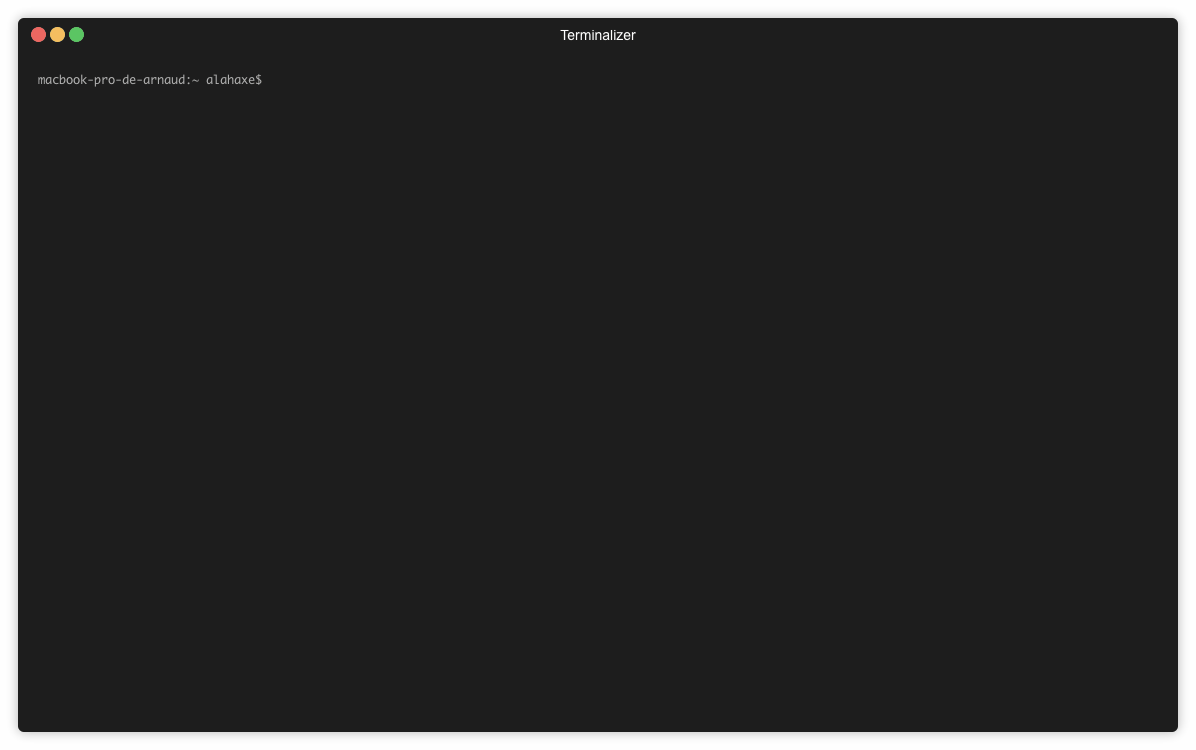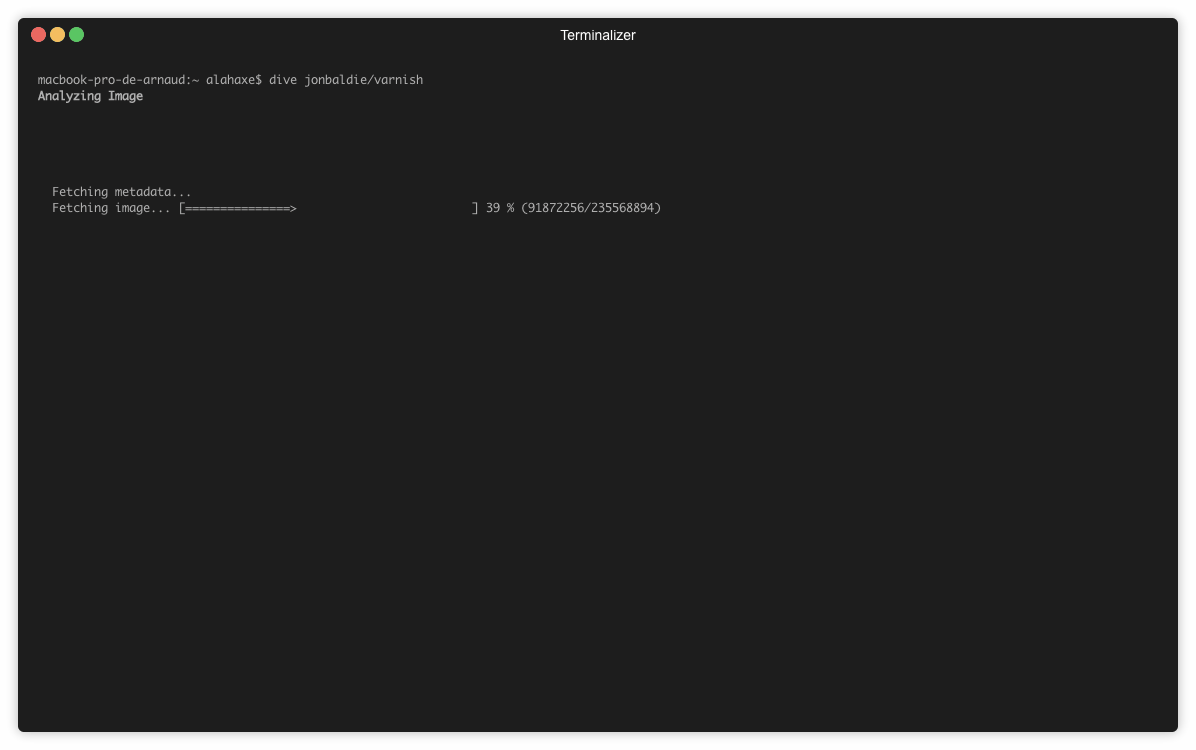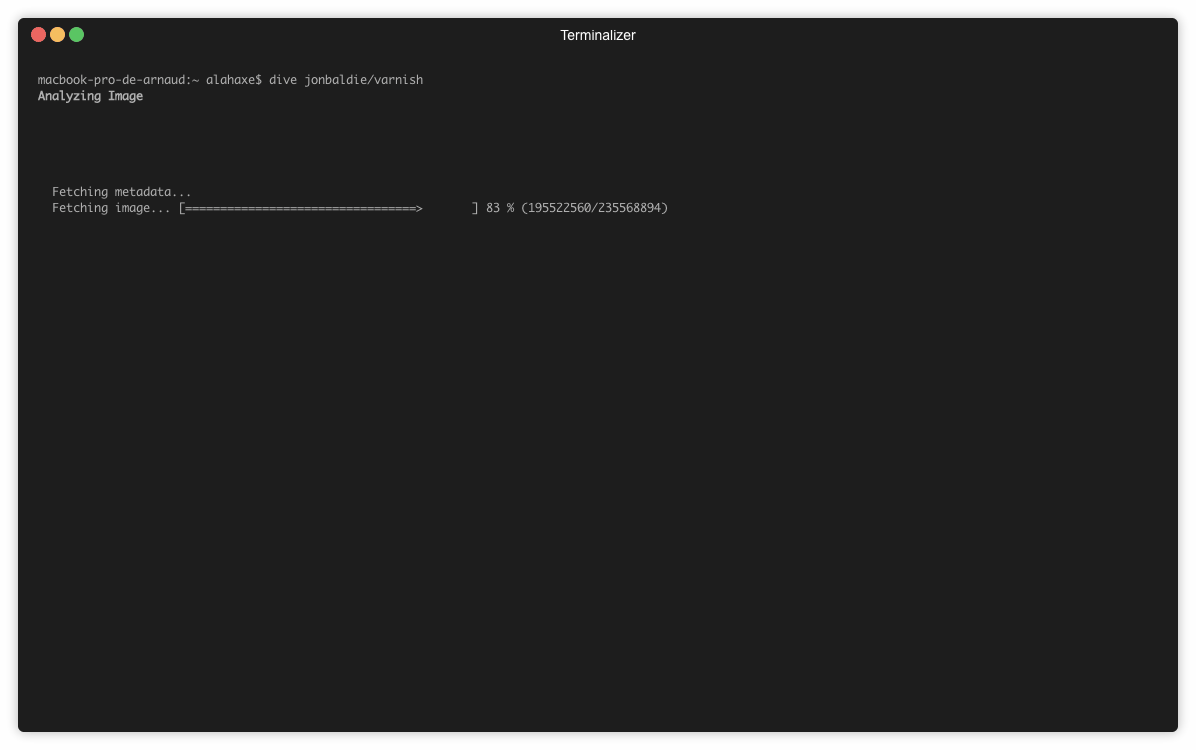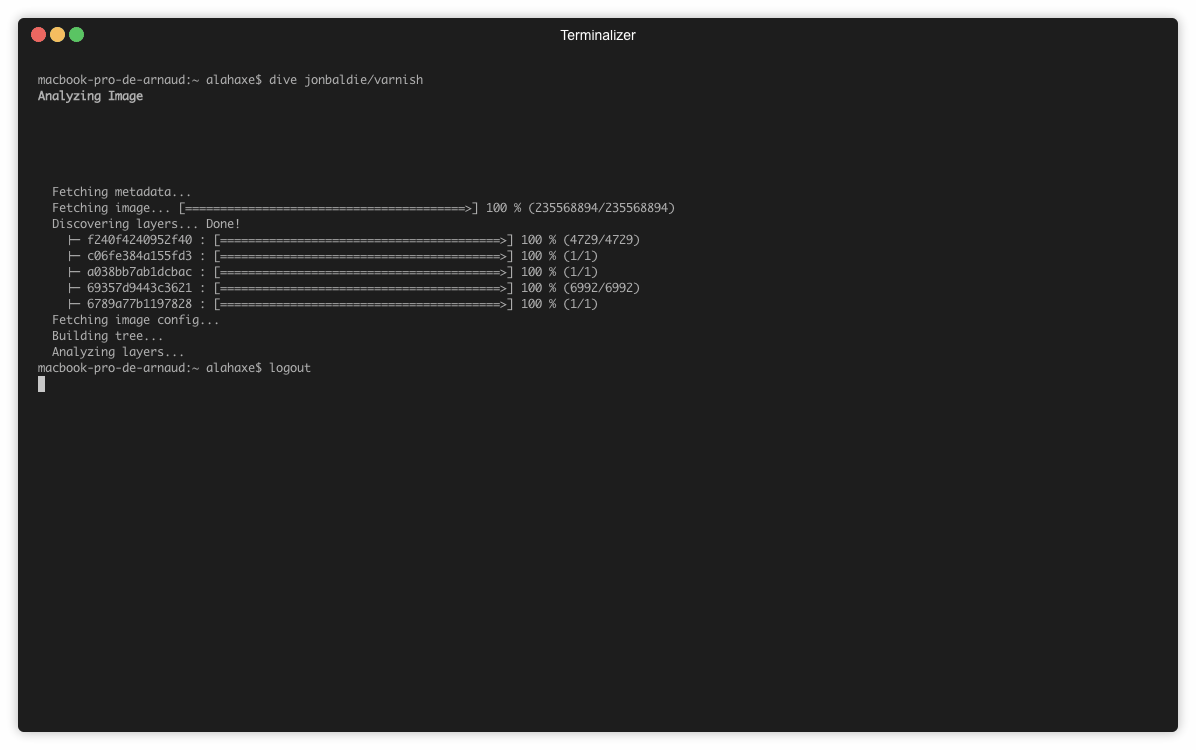
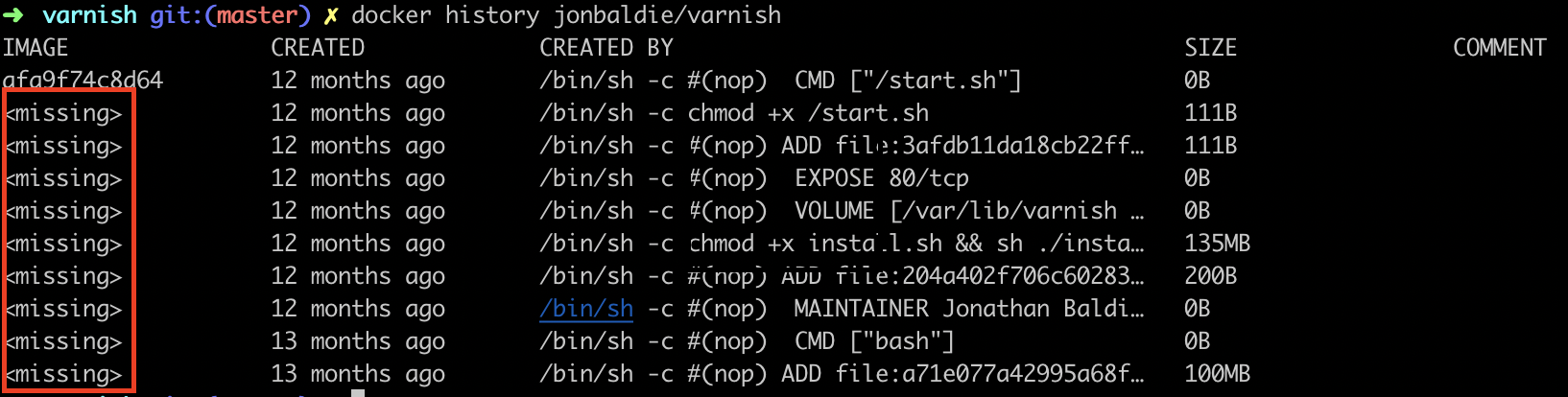
Sur l’image on a 5 layers :
L’image de base
L’ajout d’un script d’installation (/install.sh)
Le résultat de l’execution du script d’install
L’ajout du script de boot (/start.sh)
Le chmod du script de boot
Vérifier les scripts présents dans l’image
Sur la base des informations données par Dive, il ne nous reste plus qu’à vérifier, si possible, le contenu des fichiers install.sh et start.sh
Pour un fichier toujours présent dans le dernier layer
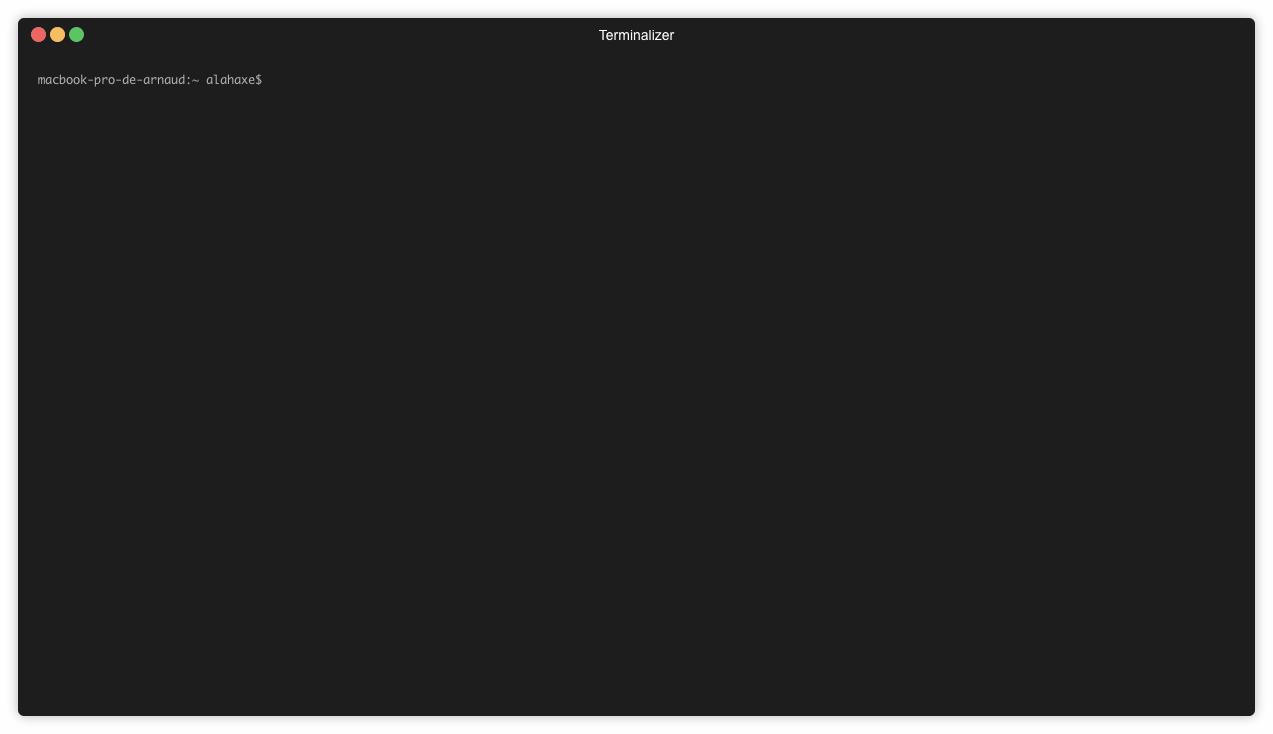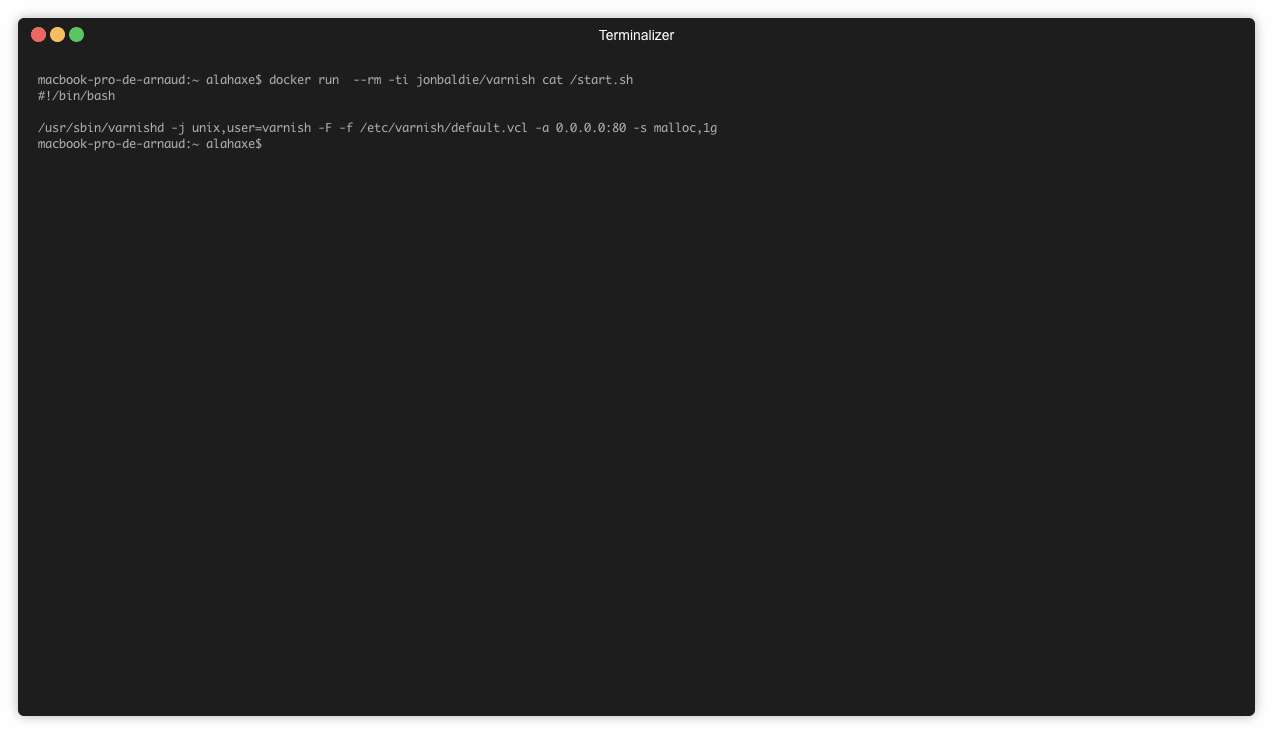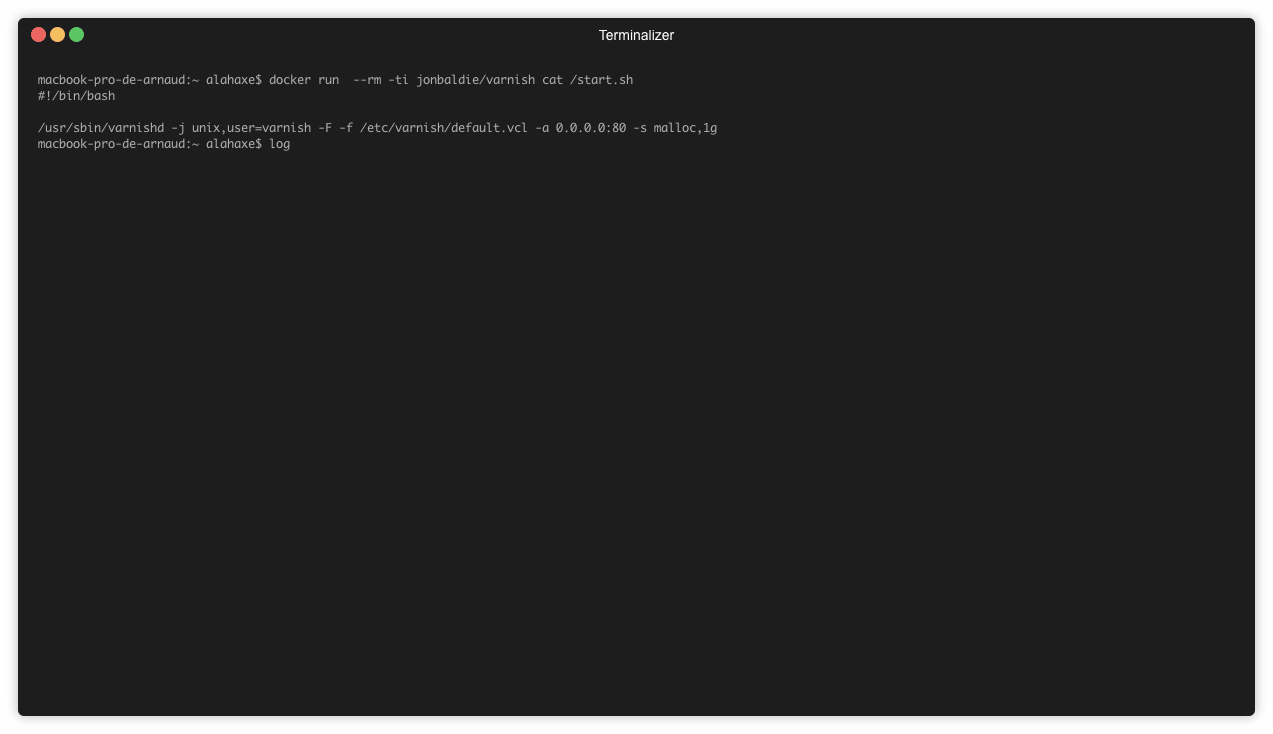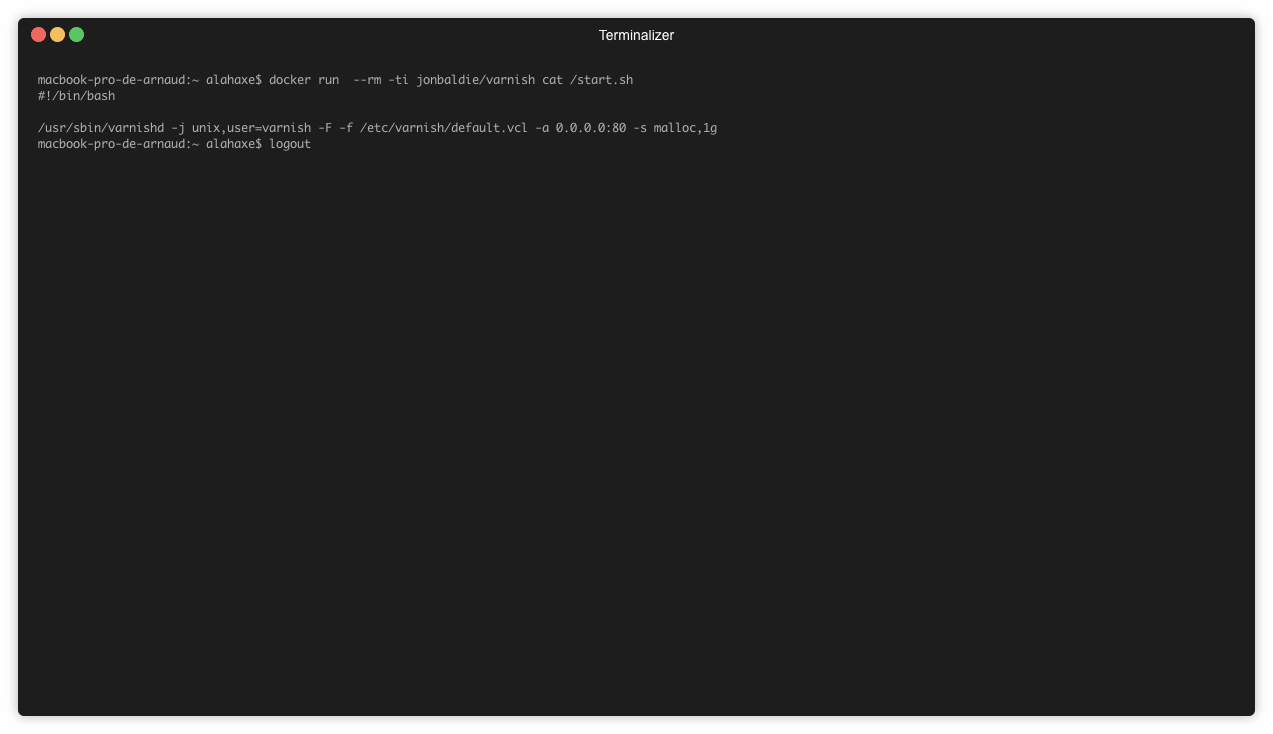
Le fichier start.sh n’est pas supprimé après l’installation. Il est donc simple de le consulter:
➜ docker run --rm -ti jonbaldie/varnish cat /start.sh
Pour un fichier non présent dans le dernier layer
Pour le fichier install.sh il ne va malheureusement pas être possible de l’afficher car il est supprimé pendant le build. Le docker history de l’image ne me donne pas d’image Id correspondant à ce layer car je n’ai pas buildé l’image sur ma machine.
Docker history sur jonbaldie/varnish
Il n’est pas possible de lancer un container sur une image qui contient le install.sh. Et c’est bien là le problème ! C’est une boîte noire.
Pour arriver à consulter ce fichier il va falloir exporter l’image et naviguer dans les layers « à la main ».
Pour voir le fichier on va récupérer le tar id du layer qui nous intéresse via Dive :
On sait donc maintenant qu’il faut regarder le contenu du tar « c06fe384a155fd3501bdb5689a4d79a18c80a63243038184f457793490b7ddde » pour trouver mon fichier install.sh.
Récupérer un fichier dans un layer docker
Vérifier l’image de base
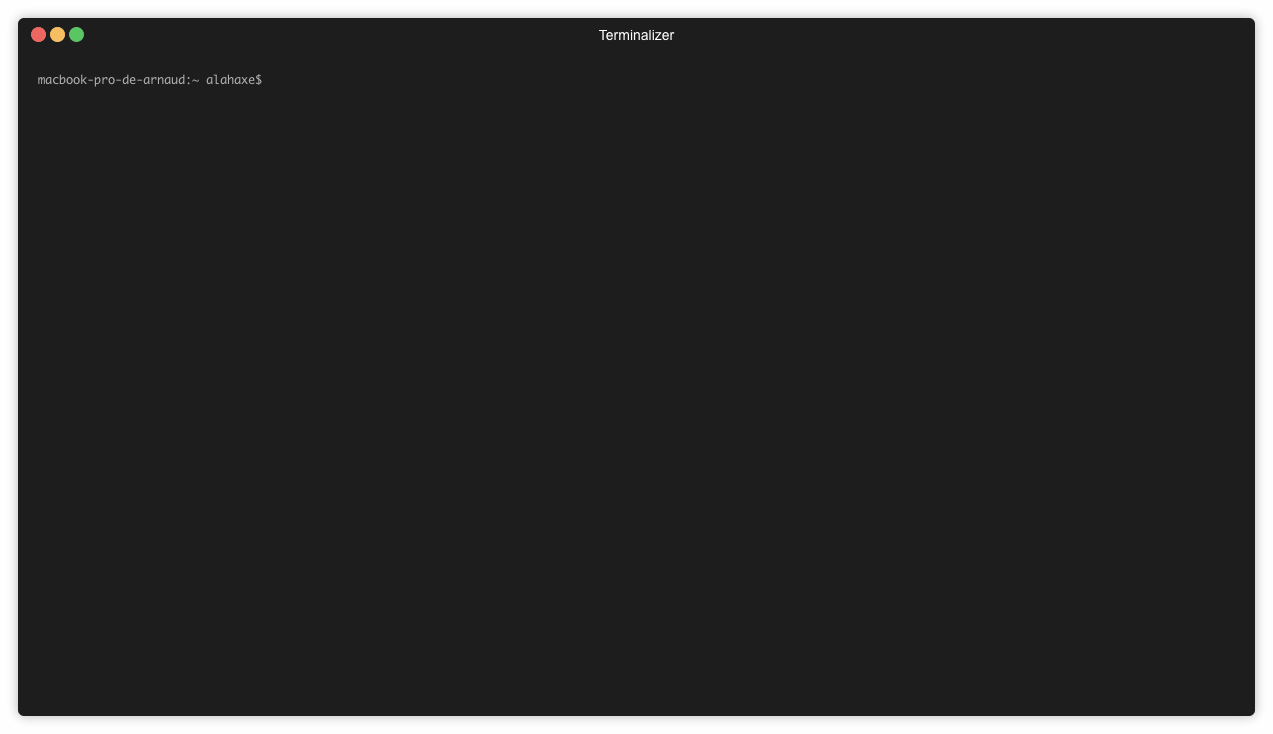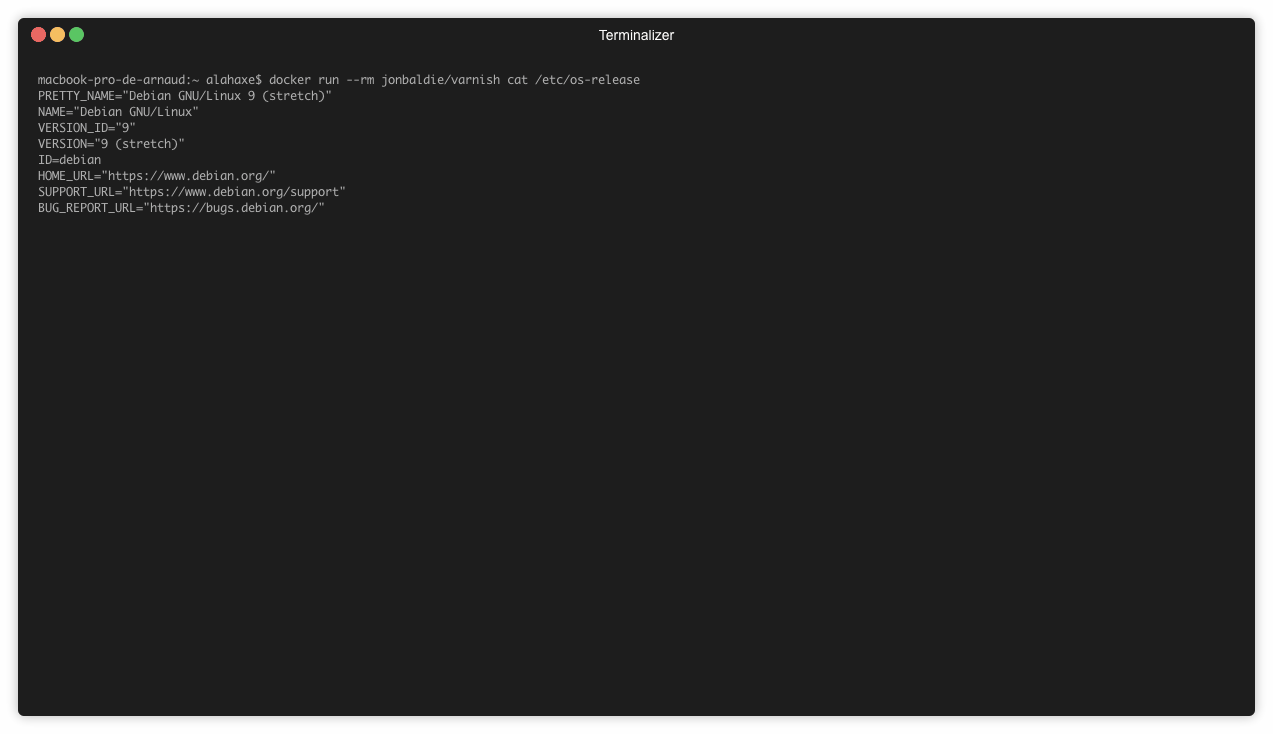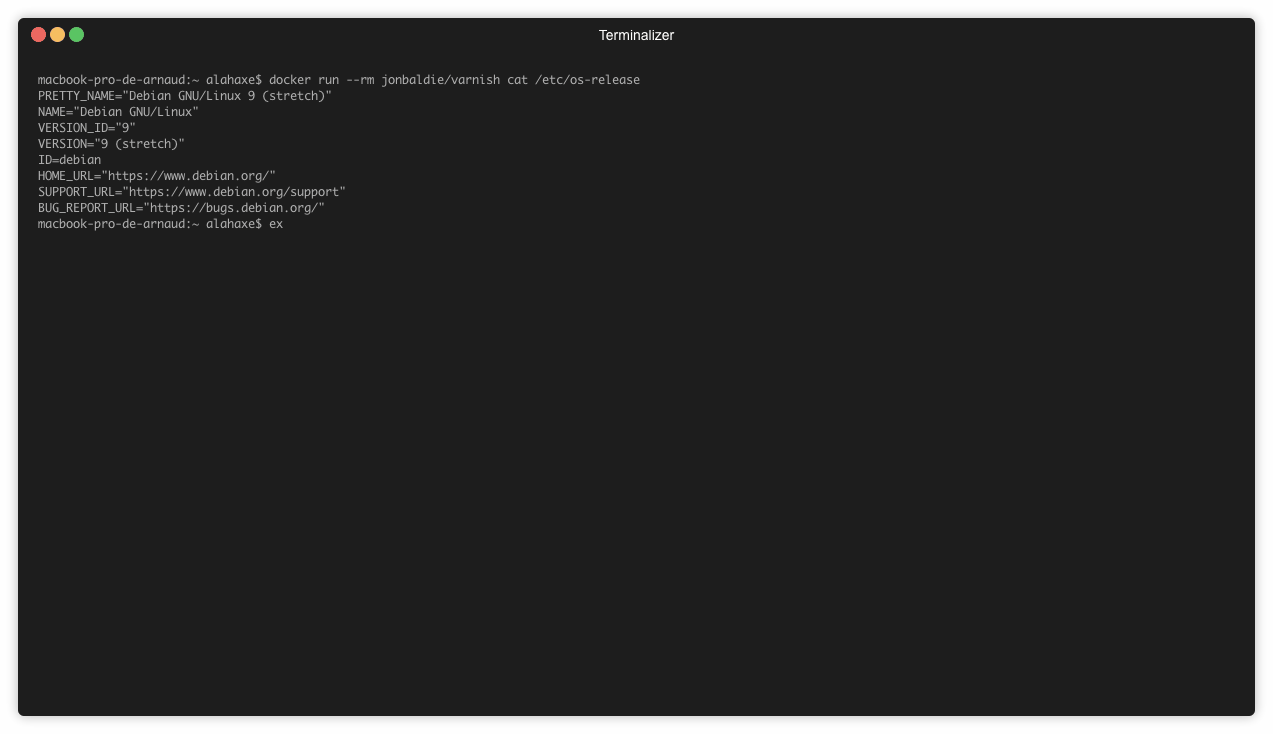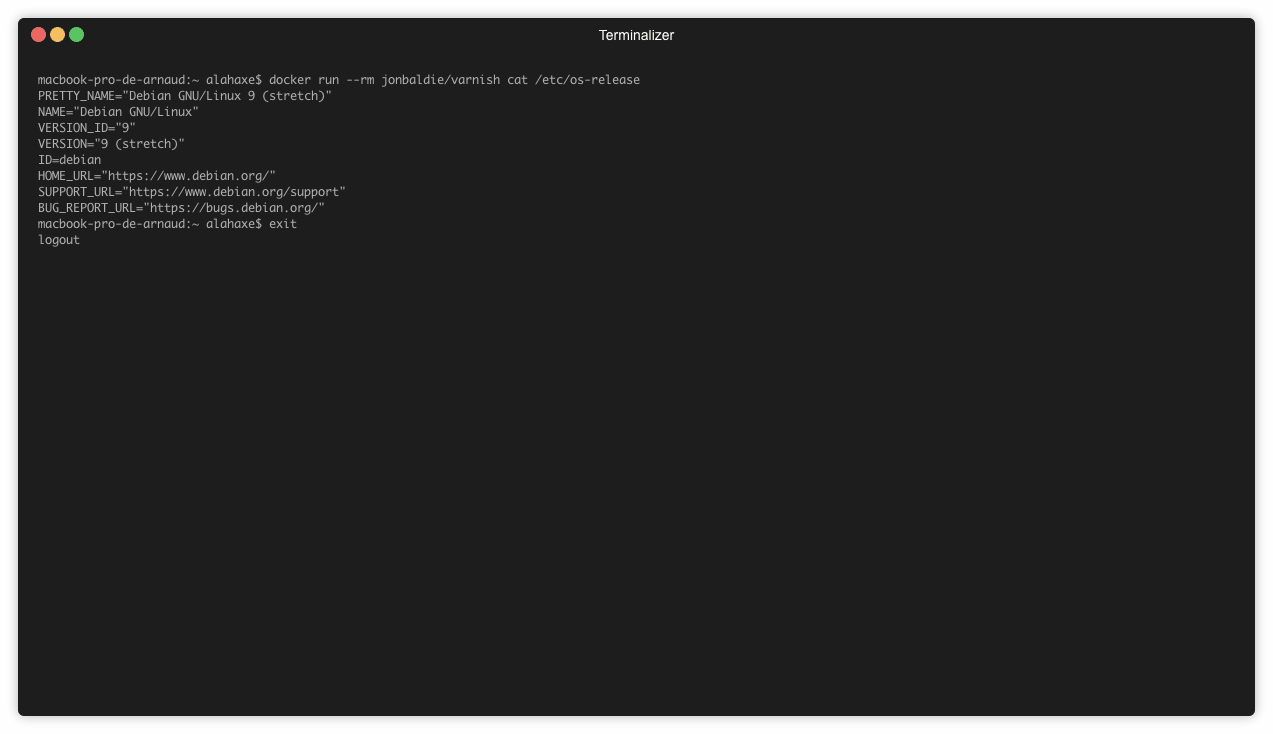
Dans notre cas l’image est construite à partir d’une debian officielle. Mais comment s’en assurer ? Est-ce que cette debian est à jour ?
Dans un premier temps on va chercher la version de debian installée :
➜ varnish docker run --rm jonbaldie/varnish cat /etc/os-release
Trouver la version de debian utilisée dans une image docker
Malheureusement je ne sais pas comment vérifier que cette debian est bien une version officielle. Je ne peux pas non plus m’assurer que les mises à jour de sécurité sont faites.
Le seul indicateur de qualité à ce niveau est de regarder les builds. Cette image est buildée automatiquement sur la Docker Cloud’s infrastructure. Ce point est primordial dans le choix d’une image non officielle car cela nous donne l’assurance que le docker file affiché est bien celui qui est utilisé pour le build.
Sur le dernier build par exemple nous avons plusieurs informations à disposition :
Building in Docker Cloud's infrastructure...
Cloning into '.'...
KernelVersion: 4.4.0-93-generic
Arch: amd64
BuildTime: 2017-08-17T22:50:04.828747906+00:00
ApiVersion: 1.30
Version: 17.06.1-ce
MinAPIVersion: 1.12
GitCommit: 874a737
Os: linux
GoVersion: go1.8.3
Starting build of index.docker.io/jonbaldie/varnish:latest...
Step 1/9 : FROM debian
---> 874e27b628fd
Step 2/9 : MAINTAINER Jonathan Baldie "[email protected]"
---> Running in 3691027bb23a
---> 6e1fd6e2af21
Removing intermediate container 3691027bb23a
Step 3/9 : ADD install.sh install.sh
---> 2d9d517255c6
Removing intermediate container 1882f5bc4a22
Step 4/9 : RUN chmod +x install.sh && sh ./install.sh && rm install.sh
---> Running in 77dd464fc5be
Ign:1 http://deb.debian.org/debian stretch InRelease
//...
Get:8 http://security.debian.org stretch/updates/main amd64 Packages [227 kB]
Fetched 10.0 MB in 4s (2119 kB/s)
Reading package lists...
Reading package lists...
Building dependency tree...
Reading state information...
The following additional packages will be installed:
binutils cpp cpp-6 gcc gcc-6 libasan3 libatomic1 libbsd0 libc-dev-bin
libc6-dev libcc1-0 libcilkrts5 libedit2 libgcc-6-dev libgmp10 libgomp1
libgpm2 libisl15 libitm1 libjemalloc1 liblsan0 libmpc3 libmpfr4 libmpx2
libncurses5 libquadmath0 libtsan0 libubsan0 libvarnishapi1 linux-libc-dev
manpages manpages-dev
Suggested packages:
binutils-doc cpp-doc gcc-6-locales gcc-multilib make autoconf automake
libtool flex bison gdb gcc-doc gcc-6-multilib gcc-6-doc libgcc1-dbg
libgomp1-dbg libitm1-dbg libatomic1-dbg libasan3-dbg liblsan0-dbg
libtsan0-dbg libubsan0-dbg libcilkrts5-dbg libmpx2-dbg libquadmath0-dbg
glibc-doc gpm man-browser varnish-doc
The following NEW packages will be installed:
binutils cpp cpp-6 gcc gcc-6 libasan3 libatomic1 libbsd0 libc-dev-bin
libc6-dev libcc1-0 libcilkrts5 libedit2 libgcc-6-dev libgmp10 libgomp1
libgpm2 libisl15 libitm1 libjemalloc1 liblsan0 libmpc3 libmpfr4 libmpx2
libncurses5 libquadmath0 libtsan0 libubsan0 libvarnishapi1 linux-libc-dev
manpages manpages-dev varnish
0 upgraded, 33 newly installed, 0 to remove and 1 not upgraded.
Need to get 30.5 MB of archives.
After this operation, 123 MB of additional disk space will be used.
Get:1 http://deb.debian.org/debian stretch/main amd64 libbsd0 amd64 0.8.3-1 [83.0 kB]
//...
Get:33 http://deb.debian.org/debian stretch/main amd64 varnish amd64 5.0.0-7+deb9u1 [690 kB]
[91mdebconf: delaying package configuration, since apt-utils is not installed
[0m
Fetched 30.5 MB in 1s (18.9 MB/s)
Selecting previously unselected package libbsd0:amd64.
Preparing to unpack .../00-libbsd0_0.8.3-1_amd64.deb ...
//...
Setting up varnish (5.0.0-7+deb9u1) ...
Processing triggers for libc-bin (2.24-11+deb9u1) ...
vcl 4.0;
backend default {
.host = "127.0.0.1";
.port = "8080";
}
---> 0953378c3b8d
Removing intermediate container 77dd464fc5be
Step 5/9 : VOLUME /var/lib/varnish /etc/varnish
---> Running in c56c31df17fb
---> e7f1ae57b0f0
Removing intermediate container c56c31df17fb
Step 6/9 : EXPOSE 80
---> Running in e1f015e6366e
---> 6000a2d9d149
Removing intermediate container e1f015e6366e
Step 7/9 : ADD start.sh /start.sh
---> 085cec1148a7
Removing intermediate container 73e8ab753261
Step 8/9 : RUN chmod +x /start.sh
---> Running in 8ab33da3607a
---> 06f67d6546ac
Removing intermediate container 8ab33da3607a
Step 9/9 : CMD /start.sh
---> Running in 3910129787df
---> afa9f74c8d64
Removing intermediate container 3910129787df
Successfully built afa9f74c8d64
Successfully tagged jonbaldie/varnish:latest
Pushing index.docker.io/jonbaldie/varnish:latest...
Done!
Build finished
Première information, l’image est bien construite à partir de l’image debian officielle comme on peut le voir à la step 1: « Step 1/9 : FROM debian ».
Seconde information, l’image a été buildée le 17 Août 2017. Toutes les failles détectées depuis cette date sur varnish et debian stretch ne sont donc pas patchées.
Pour les images qui ne sont pas buildées automatiquement sur la plateforme je ne sais pas si c’est possible de vérifier l’intégrité de l’image de base. J’ai tenté plusieurs approches mais comme l’image utilise une « latest » et qu’elle a été remplacée par une nouvelle version je ne vois pas comment faire pour retrouver mon layer. Si vous avez une solution, je suis preneur.
Builder ses propres images
La solution qui présente le moins de risques est de builder soi-même ses images à partir des Dockerfiles mis à disposition par les contributeurs. De cette manière on peut faire une revue complète du code et des dépendances. En buildant moi-même mon image je pourrais avoir une version plus à jour de debian et de varnish.
Builder une image docker depuis les sources github
Conclusion
Il faut absolument se méfier des images mises à disposition sur le Dockerhub. Avant d’utiliser une image on doit se poser au minimum les questions suivantes :
Est-ce que l’image est officielle ou buildée automatiquement ?
Si non, est-ce que les sources sont disponibles ?
Si oui, est-ce que le dockerfile présenté est vraiment celui qui a servi à builder l’image ?
De quand date la dernière build ?
Au moindre doute il est préférable de builder sa propre version de l’image ou d’en utiliser une autre.
Prefixr est un outil, en version alpha, qui vas vous aider dans le développement de vos designs. En effet, le site vous propose de prendre n’importe quel code CSS et de vous en ressortir un code CSS compatible sur tous les navigateurs.
Bien que ceci soit déjà pas mal, cela implique de faire des aller retours entre votre éditeur et votre navigateur pour tester et modifier votre CSS. C’est pourquoi les développeur ont mis en place une api accessible depuis les éditeurs de texte évolués afin d’utiliser le service sans aller sur le site.
Pour cela il faudra créer une nouvelle commande dans votre éditeur qui exécutera :
En conclusion Prefixr est un outil très intéressant et offrant un gain de temps considérable. Cependant il vas nécessiter des mise à jours régulières pour s’adapter au mieux à toutes les règles du CSS3.
WordPress est un des CMS les plus utilisés dans le monde. Il permet de créer rapidement et très simplement un blog, mais aussi des sites Internet en tous genres. Avec les bonnes extensions, vous pouvez même en faire un site de e-commerce. Son avantage est principalement son optimisation pour le référencement. En effet, si vous avez du contenu intéressant, il sera facilement et rapidement indexé sur les moteurs de recherche. Un des autres avantages de WordPress est sa grande flexibilité. Vous pouvez réussir à faire énormément de choses juste en ajoutant des extensions. Voici donc une liste des extensions que vous pourrez directement installer depuis votre interface administrateur. Pour installer une extension, rendez-vous dans Extensions>Ajouter.
Extensions orintées référencement
Beaucoup d’extensions existent pour optimiser votre référencement, mais il faut faire un choix et éviter de trop alourdir votre WordPress.
SEO ALRP : permet de rajouter automatiquement à la fin de vos articles des liens vers d’autres articles de la même thématique
Simple Tags : permet de trouver simplement les mots clés pour vos articles
Tweet, Like, Google +1 and Share : permet l’ajout de liens de partages sur les réseaux sociaux
SEO Ultimate : pour mettre en place des balises meta différentes pour chaque page
Utilitaire
WordPress Backup : permet de faire une sauvegarde de vos images, plugins et thèmes WordPress
Broken Links Remover vérifie tous les intervalles de temps défini, les liens du site afin de trouver des liens ou des images morts.
Mobile Smart : permet la détection des appareils mobiles et la sélection d’un thème WordPress adapté.
Exploit Scanner teste le code de votre WordPress afin de tenter d’y trouver des failles de sécurité
Post View permet de suivre le nombre de visites de vos articles, de les classer par fréquentation, de faire des graphiques avec les données…
Optimisation
DB Cache Reloaded : Mise en cache des résultats des requêtes SQL
WP Widget Cache permet une gestion pointue du cache de vos widgets
H5AI est un projet développé avec HTML5 qui a pour but de remplacer la page indexof par défaut de apache. C’est dans cette optique que H5AI propose plusieurs types de vue, un moteur de recherche interne ou encore un bandeau cliquable nous indiquant notre position dans l’arborescence de fichiers, depuis le root du dossier où H5AI est mis en place.
Voici un exemple en images du type de rendu que vous pouvez avoir sur un dossier contenant plusieurs types de fichiers différents. Vous pouvez remarquer que le projet détecte le type de chacun des fichiers afin d’afficher la bonne icône.
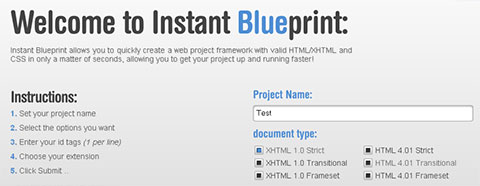
Instant Blueprint est un service en ligne qui vous permet en quelques clics de mettre en place une architecture de base pour votre nouveau projet de site Internet. En effet, après avoir renseigné quelques informations, il va vous générer automatiquement le squelette de votre site Internet.
Pour utiliser cet outil, il vous faut renseigner :
Titre du projet
Le doctype désiré
Le framework javascript à inclure
Comment inclure le framework (local ou distant, compressé ou normal)
L’extension du fichier index (html, htm, php, asp)
Que mettre dans le dossier include (config.php et/ou fonction.php)
Centrer ou non le contenu du site
Les principales div de la page
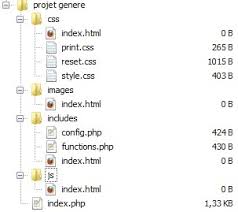
Voici le squelette généré :
A partir de ces quelques informations, Instant Blueprint génère le projet et vous propose de le télécharger. Bien entendu, tout reste à faire, mais la partie rébarbative est déjà faite.
Toutefois, il faudra penser à changer le charset par défaut, histoire de le passer en UTF-8 et ainsi se simplifier la vie niveau encodage.